이전 글 [Stock Research] 1.2. 머신러닝 모델 비교까지 주가 데이터셋 생성과 머신러닝 모델 비교를 통해 baseline model을 생성했다. 이번 글 부터는 데이터 전처리를 진행한다. 모델을 이전 글에서 선택했던 baseline 모델로 fix하고, 데이터의 질을 높임으로써 성능을 향상시킨다. 그 첫번째로 주가데이터셋에 보조지표를 추가하여 설명변수의 크기를 늘린다.
목차
주식 데이터의 보조지표
보조지표 추가
모델 학습
import pandas as pdimport numpy as npfrom tqdm import tqdmimport FinanceDataReader as fdrimport pymysqlimport warningswarnings.filterwarnings('ignore')import tafrom ipywidgets import interact, interact_manualimport matplotlib.pyplot as pltimport seaborn as snsimport plotly.graph_objects as goimport plotly.offline as pyo%matplotlib inline%pylab inlinepylab.rcParams['figure.figsize'] = (12,5)
%pylab is deprecated, use %matplotlib inline and import the required libraries.
Populating the interactive namespace from numpy and matplotlib
(1) 주식데이터의 보조지표
주식데이터에서 보조지표란 기술적지표라고도 불리며, 다양한 각도와 계산식, 통계 등을 바탕으로 기본적 분석 방법들과 조합하여 보다 폭 넓은 시장 예측을 가능하게 도와주는 차트 분석 도구이다.
[17:26:28] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
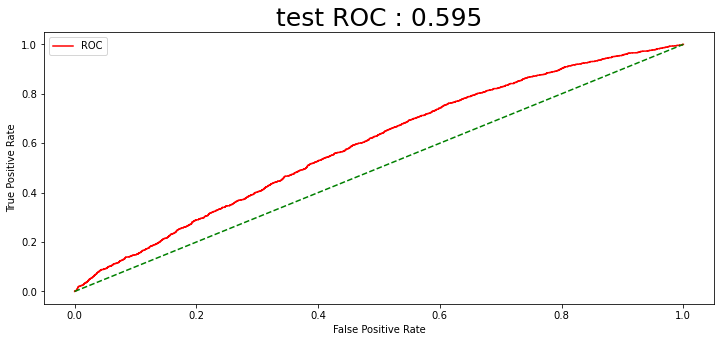
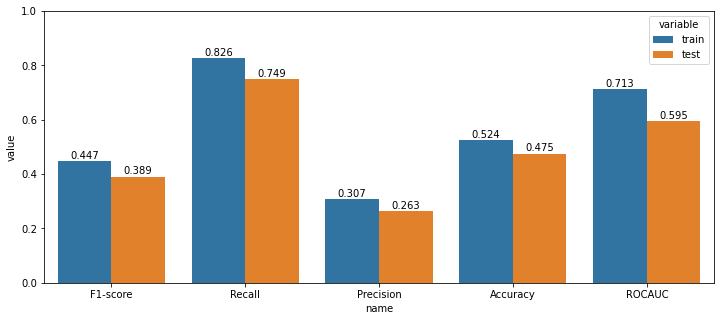
rocauc score는 0.595의 성능을 보였다. 데이터의 기간을 늘리고, 보조지표를 추가함으로써 지난 글의 Baseline Model의 0.56 보다 성능이 향상되었다.
다음 글에서는 현재 사용하고 있는 통합 종목 주가 데이터셋의 종목별 가격이 모두 다른 점을 보완하기 위해 데이터를 표준화하는 시간을 가진다.
 출처-네이버 증권
출처-네이버 증권