이전 글 ( [Stock Research] 2.3. CCI를 이용한 주가 데이터 필터링) 까지 데이터 전저리를 통해 baseline model에 비해 성능을 향상시킬 수 있었다. 이번 글에서는 설명가능 AI 기법중에서도 SHAP value가 무엇인지 알아보고, 앞서 학습했던 CCI 구간 별 XGBoost 모델을 사용하여 SHAP value를 계산함으로써 주가 이진분류 예측에 영향을 미친 중요 변수를 해석해 본다. 여기서 summary plot의 결과로 나온 상위 중요 변수로 데이터를 필터링하여 특정 집단을 구성하고, 공통된 특징이 있는지 확인한다.
목차
설명가능 AI (XAI), SHAP value란?
CCI 구간 별 summary plot 비교
라이브러리 import
import pandas as pdimport numpy as npfrom tqdm import tqdmimport pymysqlimport warningswarnings.filterwarnings('ignore')from ipywidgets import interact, interact_manualimport matplotlib.pyplot as pltimport seaborn as snsimport plotly.graph_objects as goimport plotly.offline as pyo%matplotlib inline%pylab inlinepylab.rcParams['figure.figsize'] = (12,5)import StockFunc as sf
%pylab is deprecated, use %matplotlib inline and import the required libraries.
Populating the interactive namespace from numpy and matplotlib
(1) 설명가능 AI (XAI), SHAP value란?
설명가능 AI (XAI, Explainable Artificial Intelligence)
오늘날 인공지능의 성능이 좋아짐에 따라 모델의 복잡도 또한 높아지게 되었다. 여기서 예측 결과에 대한 모델의 신뢰성 문제가 따라오게된다. 설명가능 AI는 이러한 문제점을 해결하여 인공지능 알고리즘으로 작성된 결과와 출력을 인간인 사용자가 이해하고 신뢰할 수 있도록 해준다.
본 프로젝트에서는 설명가능 AI 기법 중에서 shap value를 활용하여 변수 중요도를 파악하고, 변환된 SHAP 표준화 데이터셋을 이용한 연구를 진행한다. SHAP(SHAPley Additional Descriptions)는 모든 기계 학습 모델의 출력을 설명하기 위한 게임 이론적 접근법이다. 게임 이론의 고전적인 shapley value를 계산하여 입력 변수와 모델의 결과값 사이의 관계를 분석하는 XAI 기법 중 하나이다.
*shapley value
-각 변수가 예측 결과물에 주는 영향력의 크기
-해당 변수가 어떤 영향을 주는지 파악
- (ex)
- 각 선수가 팀 성적에 주는 영향력 크기
- 해당 선수가 어떠한 영향을 주는가
- (선수 A가 있는 팀 B의 승률) - (선수 A가 없는 팀 B의 승률) = 7%
-> “선수 A는 팀 승률에 7% 만큼의 영향력이 있다.”
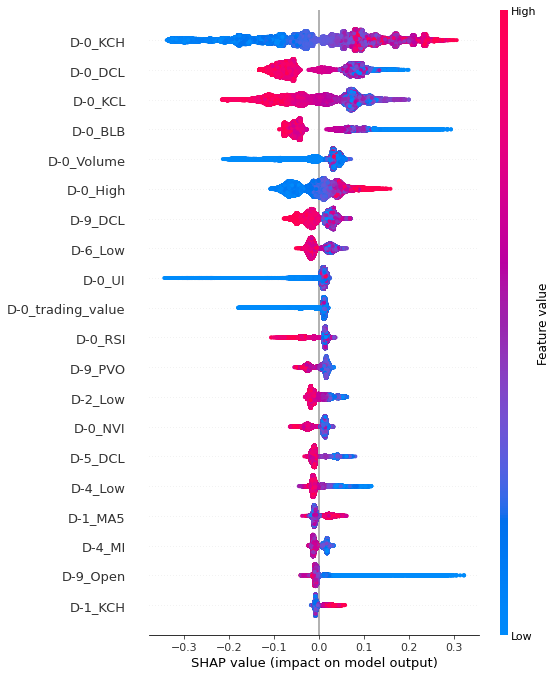
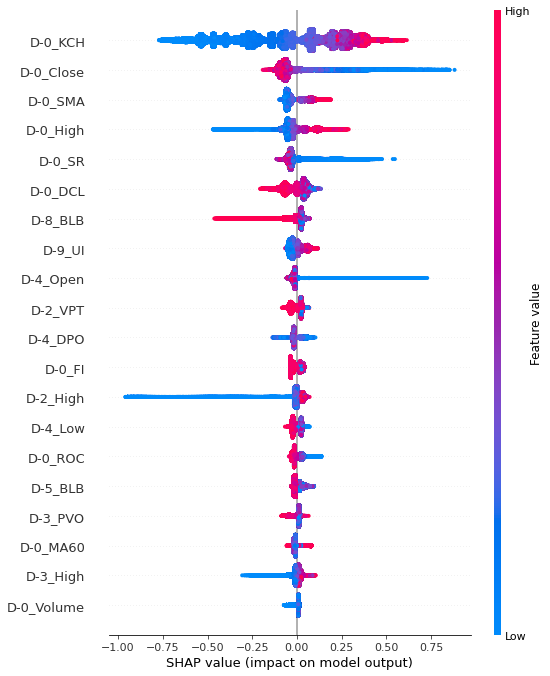
Summary plot에서 X축은 SHAP 값으로, 모델 예측 값에 영향을 준 정도의 수치를 의미한다. (-1, 1) 사이의 값이며 영향력이 없을 수록 0에 가까운 값이다. 이러한 SHAP value가 양수 값이면 긍정적인 영향 (양의 영향), 음수 값이면 부정적인 영향 (음의 영향)을 끼쳤음을 뜻한다. 해당 모델에서는 양수의 값이 클 수록 label 1로 예측하는 데 영향을 많이 미쳤다는 뜻으로 해석할 수 있다. Y축은 설명 변수이고, 색깔은 설명 변수의 개별 데이터 값의 크기를 말한다. 빨간색일 수록 데이터의 값이 상대적으로 크고, 파란색일 수록 값이 상대적으로 작은 데이터임을 뜻한다.
shap.summary_plot(shap_values_1, df_trainX_1)
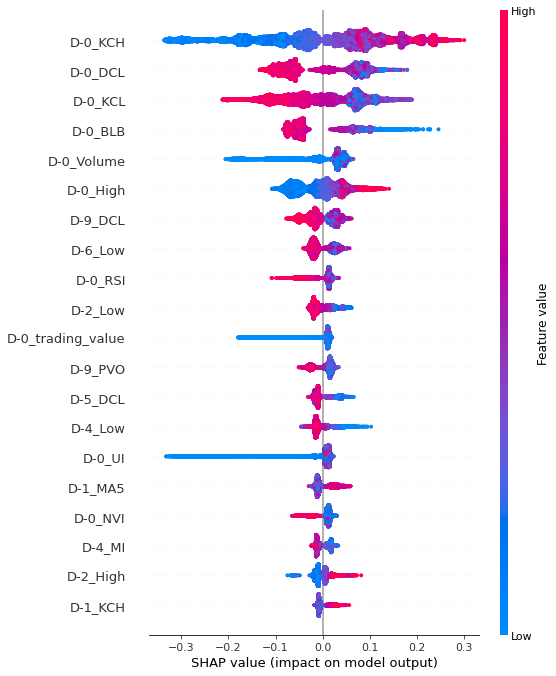
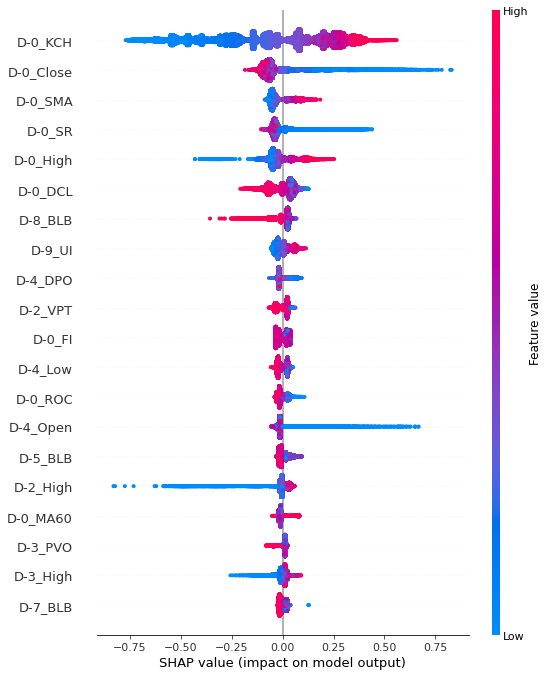
Test dataset summary plot
shap.summary_plot(shap_values_test_1, df_testX_1)
중립구간에서 train, test 데이터셋의 중요 변수 상위 6개가 동일하게 나왔음을 알 수 있다. 중요도 상위 설명 변수 3개를 해석해보면, D-0_KCH의 값이 클 수록 양의 영향 (다음 날 종가 2% 상승할 것이라 예측하는 데 영향)을 미쳤으며, D-0_DCL 의 값이 작을 수록 양의 영향, D-0_KCL의 값이 작을 수록 양의 영향을 끼쳤다.
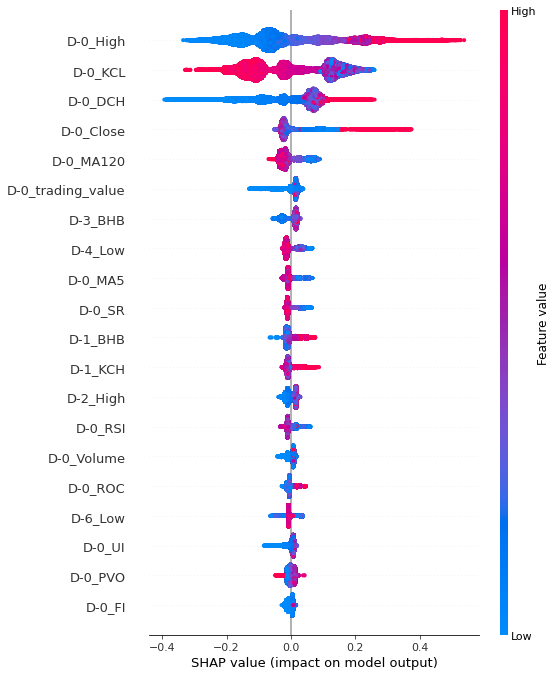
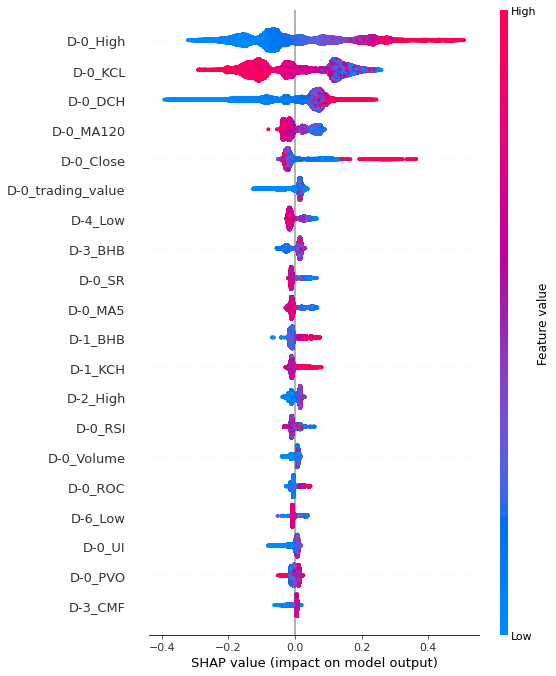
과매도구간 또한 train, test 데이터셋이 유사한 변수 중요도를 가졌다. 과매도구간은 모델 학습 당시 모델의 성능이 가장 좋게 나왔으며, summary plot 에서도 색깔의 경계가 가장 뚜렷하게 나타났다. D-0_KCH의 값이 클 수록, D-0_Close의 값이 작을 수록, D-0_SMA 값이 클 수록 양의 영향을 미쳤다고 해석할 수 있다.
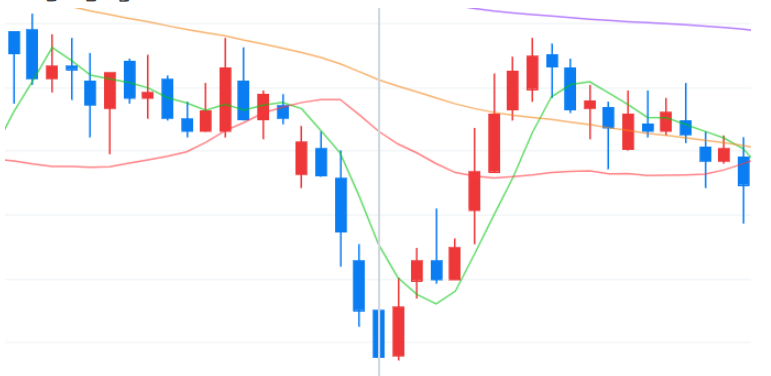
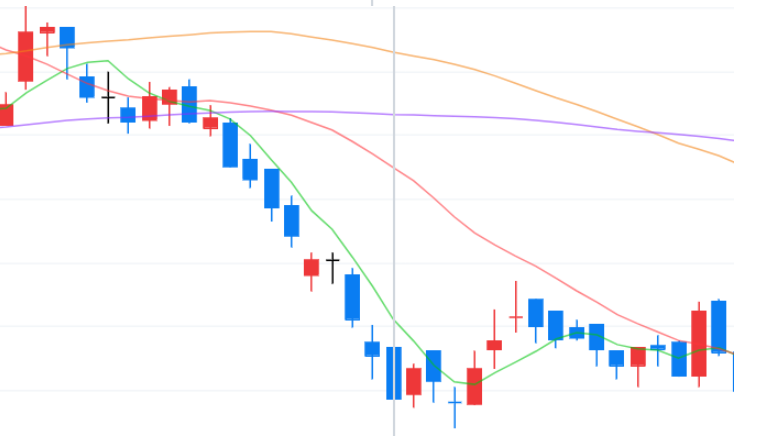
상위 변수 3개로 필터링 한 데이터
색의 경계가 가장 뚜렷하게 나타난 과매도 구간에서 상위 변수 3개를 이용하여 데이터를 필터링 하고, 특징이 나타나는지 확인해본다.
df_testX_3['Code'] = lst_code_date_test_3[:, 0]df_testX_3['Date'] = lst_code_date_test_3[:, 1]df_shap_test_3 = pd.DataFrame(shap_values_test_3, columns=lst_col_info)condition1 = df_shap_test_3['D-0_KCH'] >0.3condition2 = df_shap_test_3['D-0_Close'] >0condition3 = df_shap_test_3['D-0_SMA'] >0.05print('조건을 만족하는 데이터의 개수:', len(df_testX_3.loc[condition1 & condition2 & condition3]))print()print("<빈도수 상위 날짜 Top 5>")display(df_testX_3.loc[condition1 & condition2 & condition3, ['Date']].value_counts().head())
본 프로젝트 방향은 SHAP을 활용하여 유사한 특징을 갖고 있는 특정 집단을 발견하고 해석해내는 것이라고 할 수 있다. 위에서 변수 중요도를 시각화 하고, 상위 3개 변수에 대하여 양의 영향을 미치는 비슷한 크기의 값인 데이터들만 필터링하여 차트를 확인하였다. 이번 글에서 SHAP value summary plot을 활용하여 직접 집단을 구성해보았다면, 다음에는 이러한 집단을 알고리즘을 사용하여, 구체적으로 형성하는 방법을 연구한다. 다음 글에서는 저장한 SHAP 표준화 데이터셋과 주가 데이터셋을 2차원 평면에 시각화 하여 군집들이 형성되는지 확인하는 시간을 가진다.