지난 글 ( 3.2 t-SNE를 사용한 주가데이터 2차원 시각화 ) 에서는 원본 주가데이터셋과 SHAP 표준화 데이터셋에 대한 t-SNE 2차원 산점도 시각화를 수행하여 SHAP 표준화 데이터셋의 군집의 경계가 더 명확하게 드러남을 확인하였다. 이번 글에서는 SHAP 표준화 데이터셋에 계층적 클러스터링 알고리즘을 적용하여 명시적으로 군집을 분류해보고, label1의 비율로 군집을 필터링하여 상승 추세 군집을 선택한다. 선택된 상승 추세 군집에서 빈도수 상위 날짜들의 개별 종목 차트를 확인하여 공통된 패턴을 검출한다.
목차
계층적 클러스터링 & 상승 추세 군집 선택
정리
라이브러리 import
import pandas as pdimport numpy as npfrom tqdm import tqdmimport pymysqlimport warningswarnings.filterwarnings('ignore')from ipywidgets import interact, interact_manualimport matplotlib.pyplot as pltimport seaborn as snsimport plotly.graph_objects as goimport plotly.offline as pyo%matplotlib inline%pylab inlinepylab.rcParams['figure.figsize'] = (12,5)plt.rcParams['axes.unicode_minus'] =Falseplt.rc('font', family='NanumGothic')import StockFunc as sf
%pylab is deprecated, use %matplotlib inline and import the required libraries.
Populating the interactive namespace from numpy and matplotlib
(1) 계층적 클러스터링 & 상승 추세 군집 선택
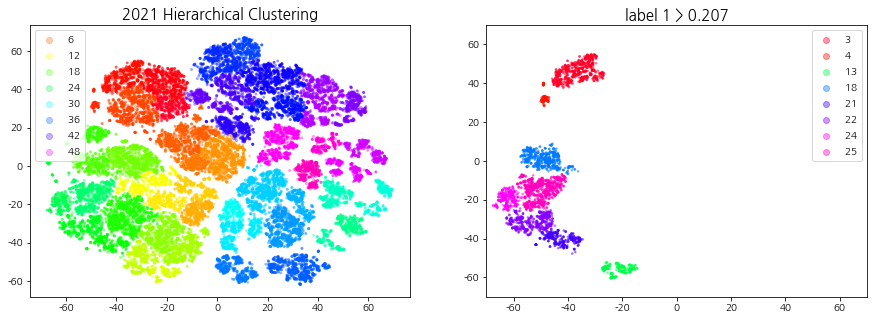
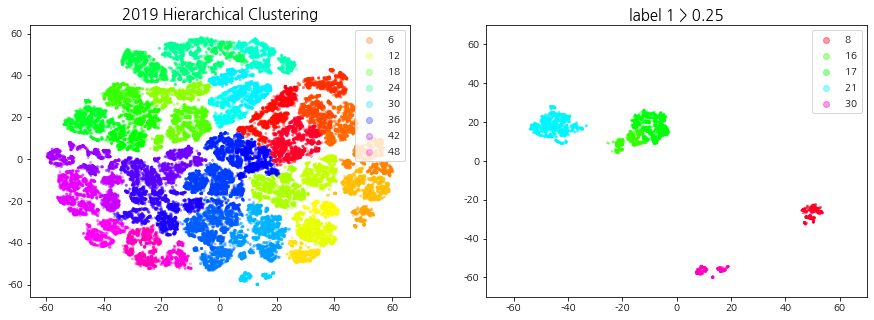
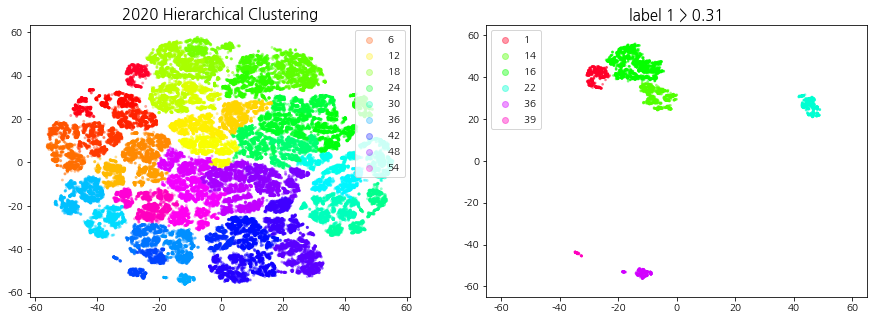
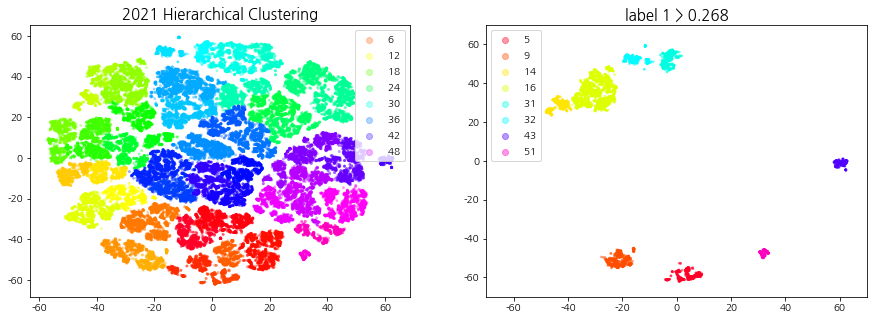
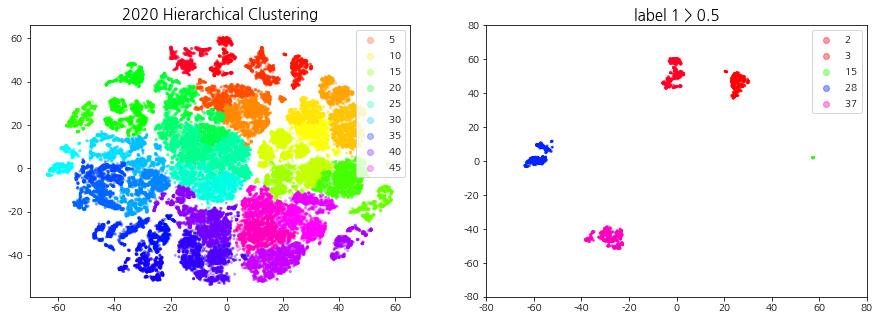
상승 추세 군집이란 기준일 (D0) 대비 다음 날 (D+1) 종가 2% 이상 상승한 데이터들이 일정 비율 이상 속하는 군집들을 의미한다. 계층적 클러스터링을 통해 생성된 군집들을 label1의 비율로 필터링하여 상승 추세 군집을 선택한다.
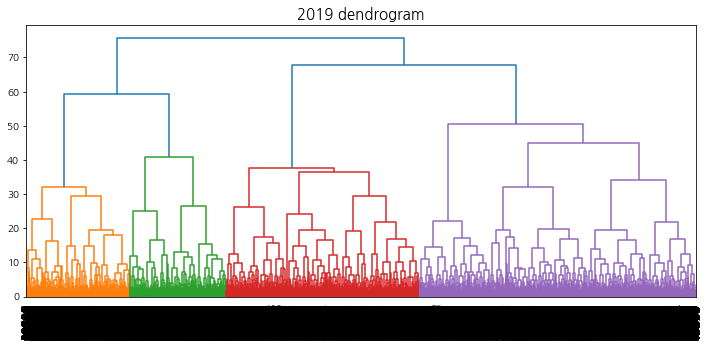
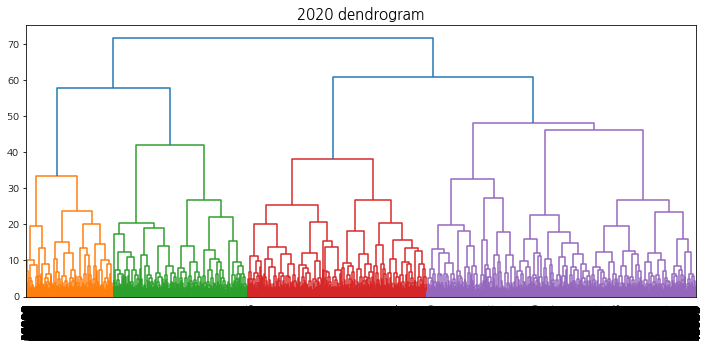
linkage, 덴드로그램 시각화 함수
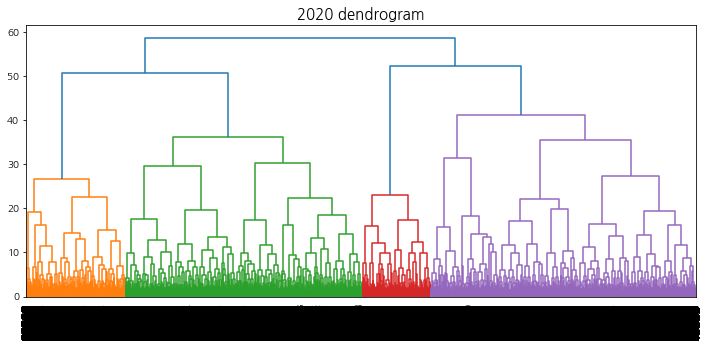
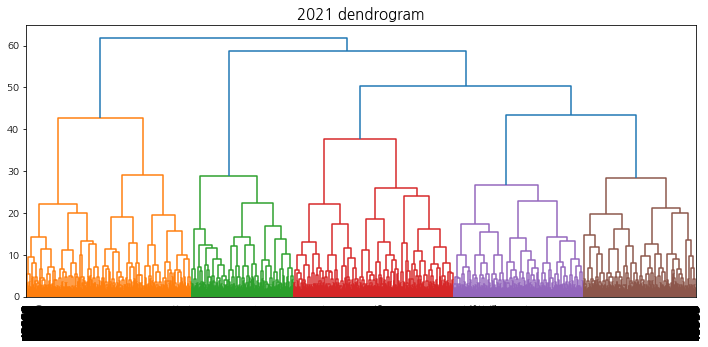
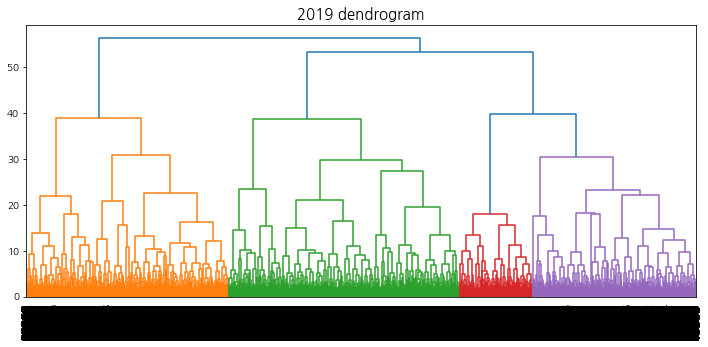
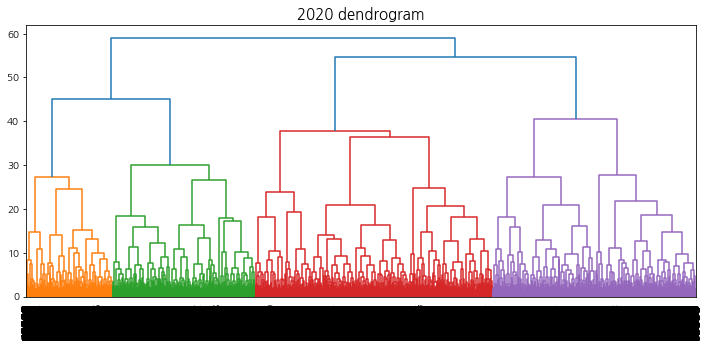
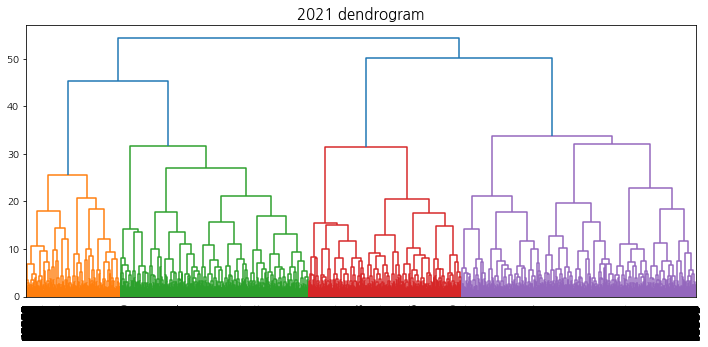
계층적 클러스터링에서의 덴드로그램 시각화를 수행하여 트리의 높이를 결정할 수 있도록 한다.
def hierarchical_clustering_plot(method, year, cci_type, dendrogram=False, n_clusters=5, min_samples=5, alpha=0.3, size=4):''' method: str / complete, average, ward year: int / 2019, 2020, 2021 cci_type:int / 1, 2, 3 dendrogram:Boolean / True, False(default) - 시간이 오래걸리므로 선택 n_clusters: int / default:5 min_samples: int / default:5 alpha: float / default: 0.3 size: int / default: 4 '''import pickle # tsne 파일 불러오기 withopen(f'np_tsne_shap_{year}_{cci_type}', 'rb') as handle: np_tsne = pickle.load(handle)if method in ('complete', 'average', 'ward'): # linkage method 선택 from scipy.cluster.hierarchy import linkage, dendrogramimport matplotlib.pyplot as plt clusters = linkage(y=np_tsne, method=method, metric='euclidean')print("linkage complete")if dendrogram: # True: 덴드로그램 시각화 plt.title(f"{year} dendrogram", fontsize=15) dendrogram(clusters, leaf_rotation=90, leaf_font_size=12,) plt.show() return clusters else:print("method를 잘못 입력하였습니다.")
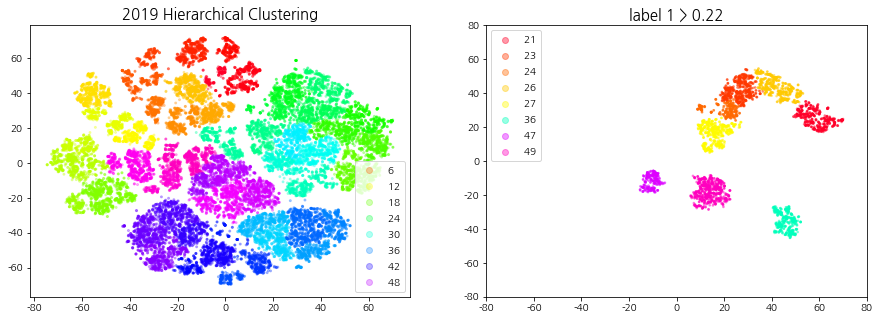
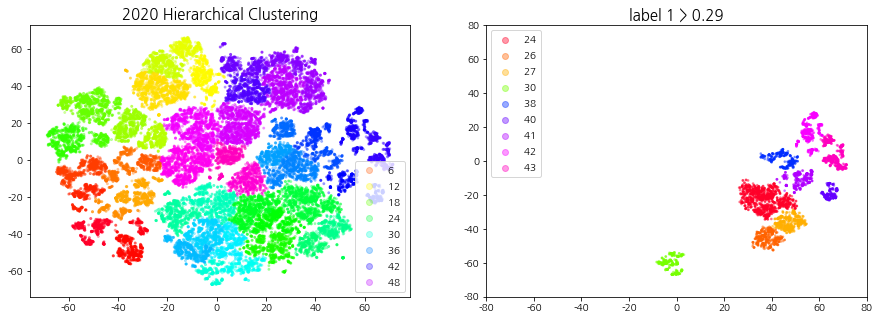
계층적 클러스터링, 상승 추세 군집 선택 시각화
덴드로그램을 참고하여 40 ~ 60개의 군집이 형성되도록 t를 설정한다. 상승 추세 군집을 선택하기 위해 적절한 ratio(특정 집단에서의 label1의 비율)값을 지정해주는데, 군집의 개수는 4 ~ 10개, 데이터의 개수는 3000 ~ 6000개 사이가 되도록 설정한다.
def fcluster_plot_and_filtering(np_clusters, year, cci_type, t=30, ratio=0.5, alpha=0.3, size=4, xlim=70, ylim=70):''' np_clusters: np.array year: int / 2019, 2020, 2021 cci_type: int / 1, 2, 3 t: int / default: 30 (덴드로그램 트리의 높이) ratio: float / default:0.5 (1의 비율이 지정) '''from scipy.cluster.hierarchy import fcluster # 지정한 클러스터 자르기import pickle withopen('all_dataset', 'rb') as handle: # Code, Date, Label 정보가 모두 들어있는 데이터셋 불러오기 dict_all_dataset = pickle.load(handle)withopen(f'np_tsne_shap_{year}_{cci_type}', 'rb') as handle: # 연도, CCI 구간에 맞는 tsne 데이터셋 불러오기 np_tsne = pickle.load(handle) df_shap_cci = dict_all_dataset[cci_type][1] df_shap_year = df_shap_cci[(df_shap_cci['Date'] >=f'{year}-01-01') & (df_shap_cci['Date'] <=f'{year}-12-31')].reset_index(drop=True) # 연도에 맞는 데이터 필터링 cut_tree = fcluster(np_clusters, t=t, criterion='distance') # 군집화 결과 데이터 print("군집의 개수:", len(pd.DataFrame(cut_tree)[0].unique())) # 군집의 개수 출력 ##### 클러스터링 시각화 fig = plt.figure(figsize=(15, 5)) ax1, ax2 = fig.subplots(1, 2) scatter = ax1.scatter(x=np_tsne[:, 0], y=np_tsne[:, 1], c=cut_tree, cmap='gist_rainbow', alpha=alpha, s=size) # 군집(cut_tree)별로 시각화 ax1.legend(*scatter.legend_elements()) ax1.set_title(f"{year} Hierarchical Clustering", fontsize=15)##### 라벨 1의 비율을 사용한 클러스터 필터링: 상승 추세 군집 선택 df_tsne = pd.DataFrame(np_tsne, columns=['component1', 'component2']) df_tsne['Code'], df_tsne['Date'], df_tsne['Label'], df_tsne['Cluster'] = df_shap_year['Code'], df_shap_year['Date'], df_shap_year['Label'], cut_tree gb = df_tsne.groupby('Cluster')['Label'].value_counts(sort=False).unstack() # 군집 별 라벨 개수 idx_label_1 = gb[gb[1]/(gb[0]+gb[1]) > ratio].index # label 1의 비율이 ratio 이상인 군집 번호print(f'label 1 > {ratio} 군집 번호: ', idx_label_1) df_tsne_1 = df_tsne[df_tsne['Cluster'].isin(idx_label_1)] # 라벨 1의 비율이 ratio 이상인 군집 추출 (상승 추세 군집)print("데이터의 개수:", len(df_tsne_1))print("종목의 종류:", df_tsne_1['Code'].nunique(), " | ", "날짜의 종류: ", df_tsne_1['Date'].nunique())##### 상승 추세 군집 시각화 ax2.set_title(f"label 1 > {ratio}", fontsize=15) scatter = ax2.scatter(df_tsne_1['component1'],df_tsne_1['component2'],c=df_tsne_1['Cluster'], cmap='gist_rainbow', s=3, alpha=0.4) ax2.legend(*scatter.legend_elements()) ax2.set_ylim(-ylim, ylim) # tsne 범위와 맞추기 ax2.set_xlim(-xlim, xlim)return df_shap_year, df_tsne_1
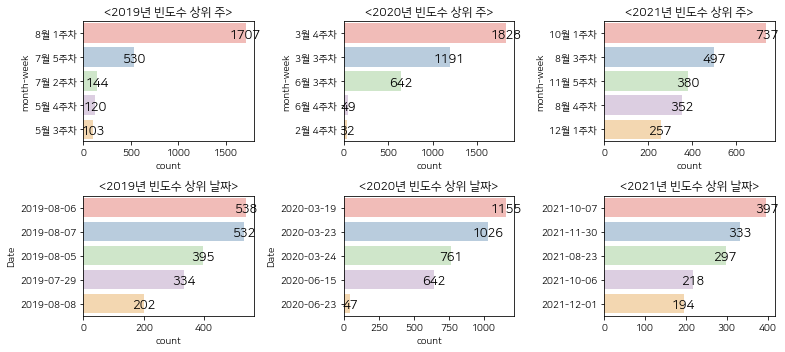
여러개의 차트 확인을 해보았을 때, 가장 큰 날짜 편중을 보였던 2020년도는 차트의 패턴이 가장 일정하게 나타났으며, 2019,2021년도는 2020년도 만큼 일정한 패턴을 보이지는 않았다. 하지만 세 연도에서 공통적으로 나오는 패턴이 존재했다. 해당 패턴을 분석해보았을 때, 위의 세 사진과 같이, 하락 추세에서 상승 추세로 전환되는 V자 형태였으며, 그 중에서도 기준일(D0)[회색 선]이 오른쪽에 위치한다는 공통점이 있었다.
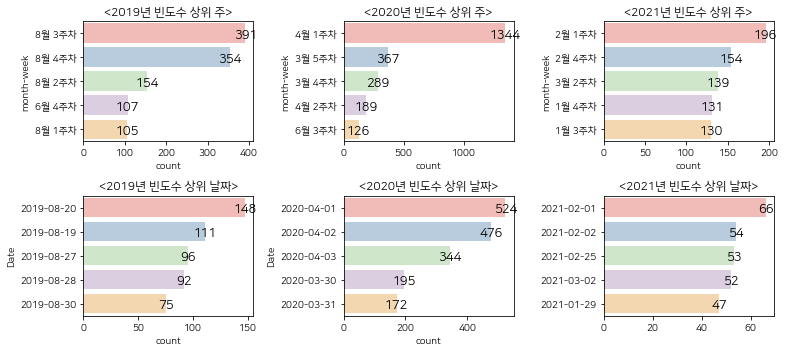
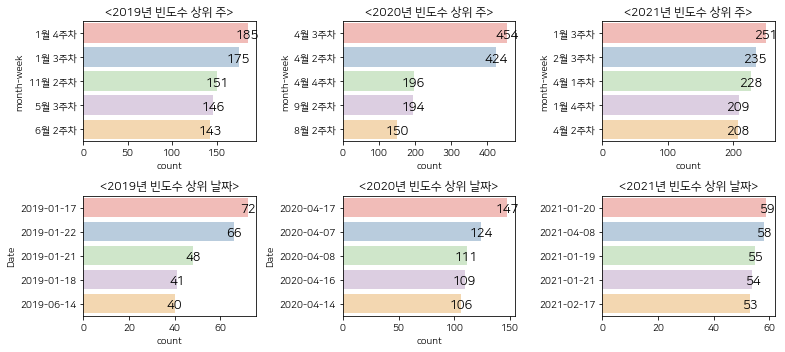
과매수구간에서 빈도수가 높은 날짜는 2019년 1월 4주차, 2020년 4월 3주차, 2021년 1월 3주차임을 알 수 있 습니다. 다른 CCI 구간에 비해 상위 빈도수의 크기 차이가 많지 않았다. 가장 높은 날짜 빈도 차이를 보이는 연도는 중립구간과 마찬가지로 2020년도였다.
연도별 상위 날짜의 개별 종목 차트 확인
연도별 상위 날짜의 랜덤 종목코드 데이터프레임 생성
상위 날짜들을 바꿔가며 실행하고, 랜덤으로 나오는 종목코드들의 개별 종목 차트를 확인한다.
과매수구간은 20일 이동평균선의 위에 극단적으로 떨어져있는 데이터들이므로, 기준일(D0)[회색 선]이 상승추세에서의 중간 ~ 끝 무렵에 위치하였다. 다른 CCI 구간보다 패턴이 가장 불규칙적이었지만, 하락추세에서 상승추세로 전환되는 V자 형태에서 상승추세 끝무렵에 위치하는 공통된 패턴을 일부 데이터에서 검출할 수 있었다.