🏢 상권 정보 분석
이번 데이터 시각화 분석에서는 공공데이터포털의 상권정보 데이터를 사용하여 서울시에 있는 상권 업종 분류 별로 살펴보며 서울시 상권업종 현황을 분석해보고, 그 중에서도 두 가지 분류(학원, 베이커리)를 집중적으로 분석해보도록 하겠습니다.
* 전공 수업시간에 진행한 내용을 토대로 가설 설정과 해석, 시각화 디자인을 재구성한 글입니다.
0. 라이브러리
import sysprint ('python' , sys.version)import numpy as npprint ('numpy' , np.__version__)import pandas as pdprint ('pandas' , pd.__version__)import matplotlib as mplprint ('matplotlib' , mpl.__version__)import matplotlib.pyplot as plt"font" , family= "Malgun Gothic" , size= 15 ) "axes" , unicode_minus= False ) # x,y축 (-)부호 표시 # 레티나 디스플레이로 폰트가 선명하게 표시되도록 합니다. from IPython.display import set_matplotlib_formats"retina" )import seaborn as snsprint ('pandas' , sns.__version__)from matplotlib.ticker import MaxNLocator# 결과 확인을 용이하게 하기 위한 코드 from IPython.core.interactiveshell import InteractiveShell= 'all' # dataframe 39 column 까지 표시 = 39
python 3.7.3 (default, Mar 27 2019, 17:13:21) [MSC v.1915 64 bit (AMD64)]
numpy 1.21.6
pandas 1.3.5
matplotlib 3.3.2
pandas 0.12.1
1. 데이터 로드
= pd.read_csv("11w/data/상가업소정보_201912_01_small.csv" , sep= '|' )3 )
상가업소번호
상호명
지점명
상권업종대분류코드
상권업종대분류명
상권업종중분류코드
상권업종중분류명
상권업종소분류코드
상권업종소분류명
표준산업분류코드
표준산업분류명
시도코드
시도명
시군구코드
시군구명
행정동코드
행정동명
법정동코드
법정동명
지번코드
대지구분코드
대지구분명
지번본번지
지번부번지
지번주소
도로명코드
도로명
건물본번지
건물부번지
건물관리번호
건물명
도로명주소
구우편번호
신우편번호
동정보
층정보
호정보
경도
위도
0
21817342
기아자동차
중랑지점
D
소매
D23
자동차/자동차용품
D23A01
자동차판매
G45110
자동차 신품 판매업
11
서울특별시
11260
중랑구
1126060000
중화1동
1126010300
중화동
1126010300202860025
1
대지
286
25.0
서울특별시 중랑구 중화동 286-25
112603000001
서울특별시 중랑구 동일로
802
NaN
1126010300102860025013386
대신빌딩
서울특별시 중랑구 동일로 802
131120
2051.0
NaN
NaN
NaN
127.079691
37.602078
1
20614940
도미노피자
용산점
Q
음식
Q07
패스트푸드
Q07A04
패스트푸드
I56199
그외 기타 음식점업
11
서울특별시
11170
용산구
1117056000
원효로1동
1117011300
원효로2가
1117011300200030004
1
대지
3
4.0
서울특별시 용산구 원효로2가 3-4
111703102007
서울특별시 용산구 원효로
210
1.0
1117011300100030004018579
NaN
서울특별시 용산구 원효로 210-1
140847
4368.0
NaN
1
NaN
126.965501
37.537384
2
16108153
케이아이에프앤비
NaN
D
소매
D01
음/식료품소매
D01A01
식료품점
G47219
기타 식료품 소매업
26
부산광역시
26110
중구
2611056000
부평동
2611012300
부평동1가
2611012300200290079
1
대지
29
79.0
부산광역시 중구 부평동1가 29-79
261104175232
부산광역시 중구 중구로29번길
22
NaN
2611012300100290079003926
NaN
부산광역시 중구 중구로29번길 22
600804
48978.0
NaN
2
NaN
129.026690
35.100566
2. 데이터 확인
2.1 기본 정보 확인
print ("== 크기 확인 ==" )print ()print ("== 컬럼 확인 ==" )print ()print ("== 정보 확인 ==" )
Index(['상가업소번호', '상호명', '지점명', '상권업종대분류코드', '상권업종대분류명', '상권업종중분류코드',
'상권업종중분류명', '상권업종소분류코드', '상권업종소분류명', '표준산업분류코드', '표준산업분류명', '시도코드',
'시도명', '시군구코드', '시군구명', '행정동코드', '행정동명', '법정동코드', '법정동명', '지번코드',
'대지구분코드', '대지구분명', '지번본번지', '지번부번지', '지번주소', '도로명코드', '도로명', '건물본번지',
'건물부번지', '건물관리번호', '건물명', '도로명주소', '구우편번호', '신우편번호', '동정보', '층정보',
'호정보', '경도', '위도'],
dtype='object')
== 정보 확인 ==
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150000 entries, 0 to 149999
Data columns (total 39 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 상가업소번호 150000 non-null int64
1 상호명 150000 non-null object
2 지점명 19939 non-null object
3 상권업종대분류코드 150000 non-null object
4 상권업종대분류명 150000 non-null object
5 상권업종중분류코드 150000 non-null object
6 상권업종중분류명 150000 non-null object
7 상권업종소분류코드 150000 non-null object
8 상권업종소분류명 150000 non-null object
9 표준산업분류코드 141065 non-null object
10 표준산업분류명 141065 non-null object
11 시도코드 150000 non-null int64
12 시도명 150000 non-null object
13 시군구코드 150000 non-null int64
14 시군구명 150000 non-null object
15 행정동코드 150000 non-null int64
16 행정동명 150000 non-null object
17 법정동코드 150000 non-null int64
18 법정동명 150000 non-null object
19 지번코드 150000 non-null int64
20 대지구분코드 150000 non-null int64
21 대지구분명 150000 non-null object
22 지번본번지 150000 non-null int64
23 지번부번지 124172 non-null float64
24 지번주소 150000 non-null object
25 도로명코드 150000 non-null int64
26 도로명 150000 non-null object
27 건물본번지 150000 non-null int64
28 건물부번지 18999 non-null float64
29 건물관리번호 150000 non-null object
30 건물명 69352 non-null object
31 도로명주소 150000 non-null object
32 구우편번호 150000 non-null int64
33 신우편번호 149996 non-null float64
34 동정보 13346 non-null object
35 층정보 90788 non-null object
36 호정보 22282 non-null object
37 경도 150000 non-null float64
38 위도 150000 non-null float64
dtypes: float64(5), int64(11), object(23)
memory usage: 44.6+ MB
데이터를 확인 해보니 결측값 있는 컬럼을 확인할 수 있습니다.
2.2 결측값 확인
위에서 확인한 결측값을 더 자세히 보기 위해 missingo 라이브러리를 사용하여 시각화해보겠습니다.
라이브러리 설치 conda install -c conda-forge missingno
import missingno as msno= msno.matrix(df)
2.3 기술 통계 값 확인
상가업소번호
시도코드
시군구코드
행정동코드
법정동코드
지번코드
대지구분코드
지번본번지
지번부번지
도로명코드
건물본번지
건물부번지
구우편번호
신우편번호
경도
위도
count
1.500000e+05
150000.000000
150000.000000
1.500000e+05
1.500000e+05
1.500000e+05
150000.000000
150000.000000
124172.000000
1.500000e+05
150000.000000
18999.000000
150000.000000
149996.000000
150000.000000
150000.000000
mean
2.041990e+07
15.332800
15748.405900
1.574901e+09
1.574852e+09
1.574853e+18
1.001320
468.930780
33.179960
1.574876e+11
153.743900
7.015159
273384.199573
17495.024287
127.593626
36.856878
std
5.213909e+06
6.798467
6756.859055
6.756845e+08
6.756859e+08
6.756858e+17
0.036308
486.121473
105.183785
6.756853e+10
277.414013
9.877446
215380.462007
19396.705618
0.940031
1.080322
min
2.895874e+06
11.000000
11110.000000
1.111052e+09
1.111010e+09
1.111010e+18
1.000000
1.000000
1.000000
1.111020e+11
0.000000
1.000000
100011.000000
1000.000000
126.768169
35.010463
25%
1.606223e+07
11.000000
11320.000000
1.132069e+09
1.132011e+09
1.132011e+18
1.000000
108.000000
3.000000
1.132041e+11
20.000000
1.000000
134851.000000
4386.000000
126.966849
35.215700
50%
2.210410e+07
11.000000
11620.000000
1.162058e+09
1.162010e+09
1.162010e+18
1.000000
333.000000
10.000000
1.162030e+11
50.000000
3.000000
142874.000000
6522.000000
127.047053
37.511174
75%
2.477166e+07
26.000000
26200.000000
2.620065e+09
2.620012e+09
2.620012e+18
1.000000
679.000000
25.000000
2.620042e+11
171.000000
9.000000
604040.000000
46563.000000
128.986009
37.560275
max
2.852486e+07
26.000000
26710.000000
2.671033e+09
2.671033e+09
2.671033e+18
2.000000
9993.000000
3784.000000
2.671042e+11
3318.000000
198.000000
619963.000000
49527.000000
129.286869
37.688821
3. 데이터 전처리
3.1 사용하지 않는 컬럼 제거
print ("== 결측치 ==" )print (df.isnull().sum ())print ()print ("== 결측치가 많은 컬럼 ==" )= df.isnull().sum ().sort_values(ascending= False ).head(9 ).index print (not_use_col)
== 결측치 ==
상가업소번호 0
상호명 0
지점명 130061
상권업종대분류코드 0
상권업종대분류명 0
상권업종중분류코드 0
상권업종중분류명 0
상권업종소분류코드 0
상권업종소분류명 0
표준산업분류코드 8935
표준산업분류명 8935
시도코드 0
시도명 0
시군구코드 0
시군구명 0
행정동코드 0
행정동명 0
법정동코드 0
법정동명 0
지번코드 0
대지구분코드 0
대지구분명 0
지번본번지 0
지번부번지 25828
지번주소 0
도로명코드 0
도로명 0
건물본번지 0
건물부번지 131001
건물관리번호 0
건물명 80648
도로명주소 0
구우편번호 0
신우편번호 4
동정보 136654
층정보 59212
호정보 127718
경도 0
위도 0
dtype: int64
== 결측치가 많은 컬럼 ==
Index(['동정보', '건물부번지', '지점명', '호정보', '건물명', '층정보', '지번부번지', '표준산업분류명',
'표준산업분류코드'],
dtype='object')
= df.drop(columns= not_use_col)
결측치가 너무 많은 컬럼은 분석에 사용할 수 없으므로 결측값 개수 상위 9개 컬럼을 추출하여 제거해주었습니다.
3.2 서울시 데이터 추출
array(['서울특별시', '부산광역시'], dtype=object)
서울시의 데이터만 분석을 진행하기 위해 서울특별시만 따로 추출하여 저장하도록 합니다.
= df[df["시도명" ] == "서울특별시" ]# 확인 "시도명" ].unique()
array(['서울특별시'], dtype=object)
4. 데이터 분석 및 시각화
1 ) 서울시 상권업종분류 통계
4.1 서울시 상권업종 분류 통계
상권업종대분류명 컬럼을 사용하여 서울시에 어떤 업종이 있고, 어떤 분류의 업종이 많이 존재하는지 통계를 내보도록 합니다.
4.1.1 상권업종대분류명 통계
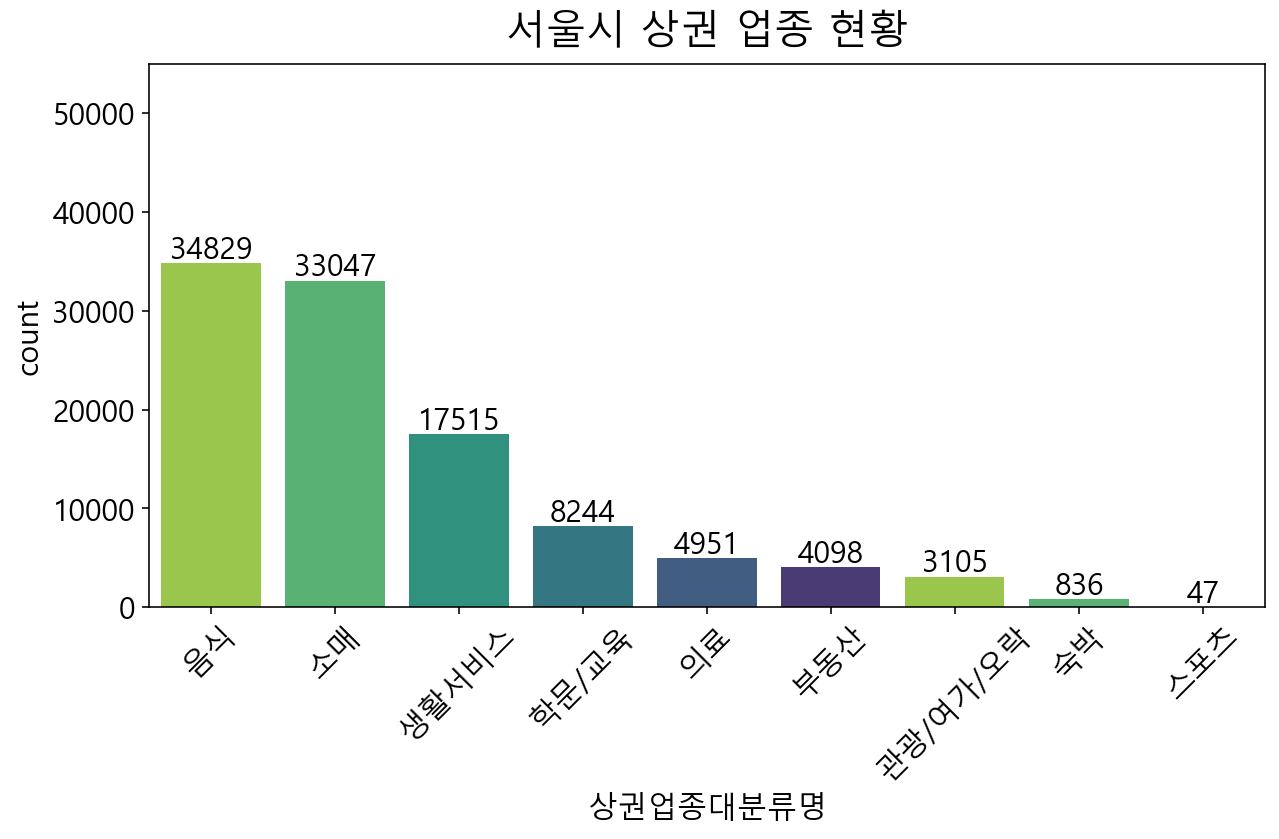
= df['상권업종대분류명' ].value_counts()= plt.figure(figsize= (10 , 5 ))= plt.title("서울시 상권 업종 현황" , fontsize= 20 , pad= 10 )= sns.countplot(data= df, x= "상권업종대분류명" , palette= sns.color_palette("viridis_r" ), order= sr_order.index)for i, b in enumerate (bars.patches):= plt.text(b.get_x()+ b.get_width()* (1 / 2 ),b.get_height()+ 500 , \ round (b.get_height()),ha= 'center' ,fontsize= 15 , color= 'black' )= plt.ylim(0 , 55000 )= plt.xticks(rotation= 45 )
상권업종대분류명으로 barplot을 그려보았습니다. 서울시에는 음식 업종이 가장 많고, 그 다음으로는 비슷하게 소매의 수가 많습니다.
4.1.2 서울시 특정 자치구의 상권 업종 통계
"시군구명" ].value_counts().head(4 )
강남구 12368
서초구 6575
광진구 5757
중구 5538
Name: 시군구명, dtype: int64
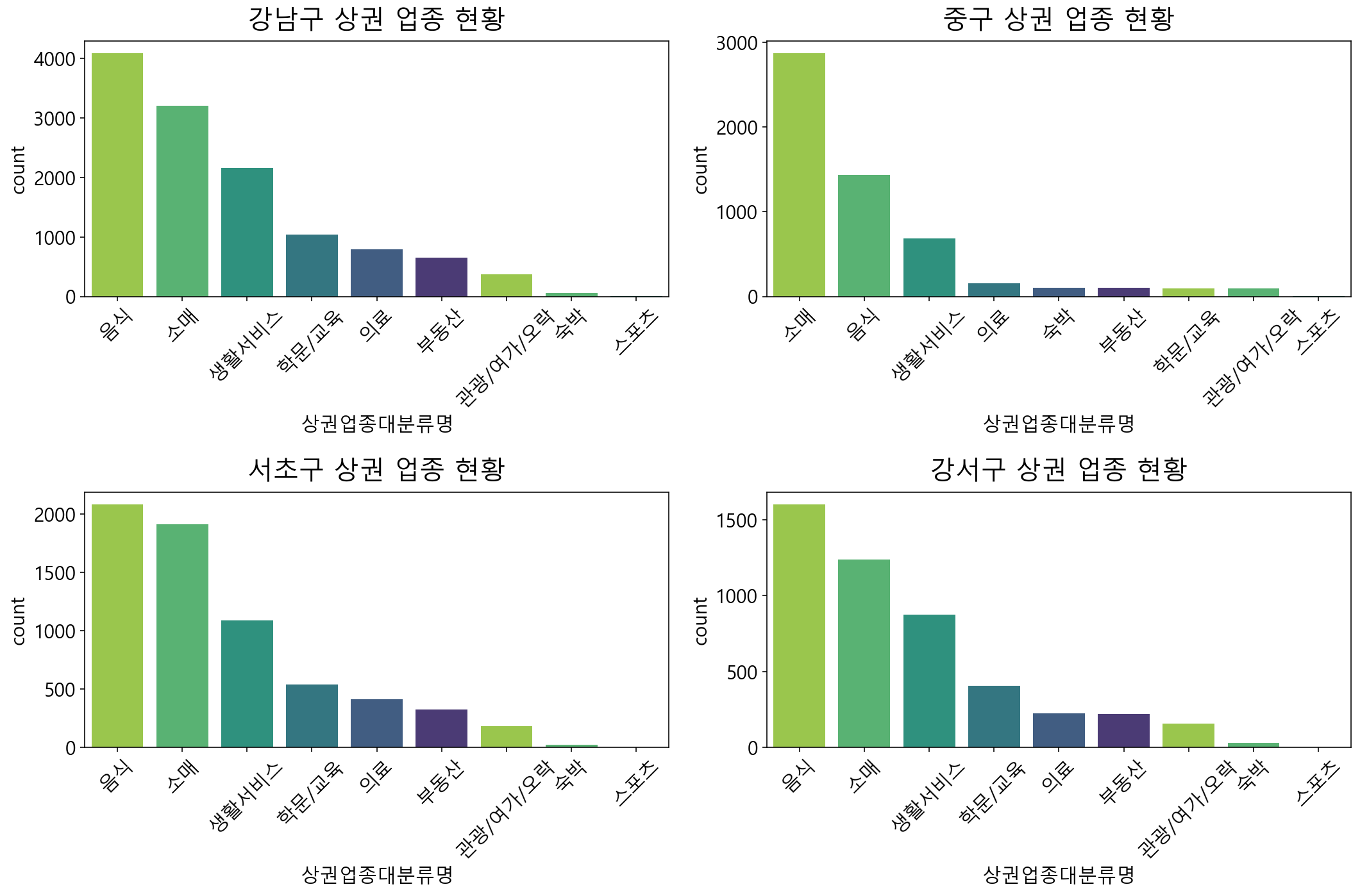
서울시 자치구 중 상권업종이 많은 4가지 자치구(강남구, 중구, 서초구, 강서구)만 뽑아 각 지역별로 어떤 업종이 많이 차지하는지 시각화 해보도록 하겠습니다.
= df[df['시군구명' ]== '강남구' ]= df[df['시군구명' ]== '중구' ]= df[df['시군구명' ]== '서초구' ]= df[df['시군구명' ]== '강서구' ]= plt.figure(figsize= (15 , 10 ))= fig.subplots(2 , 2 ).flatten() for idx, df_r in enumerate ([df_gn, df_j, df_s, df_gs]):= sns.countplot(data= df_r, x= "상권업종대분류명" , = sns.color_palette("viridis_r" ), = df_r["상권업종대분류명" ].value_counts().index, = axes[idx])= axes[idx].set_xticklabels(labels= df_r["상권업종대분류명" ].value_counts().index, rotation= 45 )= axes[idx].set_title(f" { df_r['시군구명' ]. unique()[0 ]} 상권 업종 현황" , fontsize= 20 , pad= 10 )
대부분 비슷한 형태를 띄는데, 중구는 조금 다르게 나타났습니다. 음식보다 소매 업종이 월등히 높았고, 학문/교육 업종은 다른 지역에 비해 현저히 낮은 것으로 보여집니다.
4.2 서울시 학문/교육 분석
서울시의 교육관련 업종 데이터만 추출하여 어떤 지역에 학원이 많이 들어서있는지, 어느 곳에 학원가가 활발한지 분석합니다.
= df[df["상권업종대분류명" ] == "학문/교육" ].copy()# 확인 "상권업종대분류명" ].unique()
array(['학문/교육'], dtype=object)
먼저 상권업종대분류명이 학문/교육인 데이터들만 추출하여 df_academy에 넣어주었습니다.
4.2.1 서울시 학문/교육 현황 시각화
"상호명" ].value_counts().head(10 )
점프셈교실 442
해법수학 15
해법영어교실 9
무지개어린이집 8
뮤엠영어 7
윤선생영어교실 7
새싹어린이집 6
숲속어린이집 6
행복한어린이집 6
삼성영어 5
Name: 상호명, dtype: int64
서울시의 상호명은 점프셈교실 이라는 상호명이 압도적으로 많습니다.
서울시 자치구별 학문/교육 업종 개수 확인하기
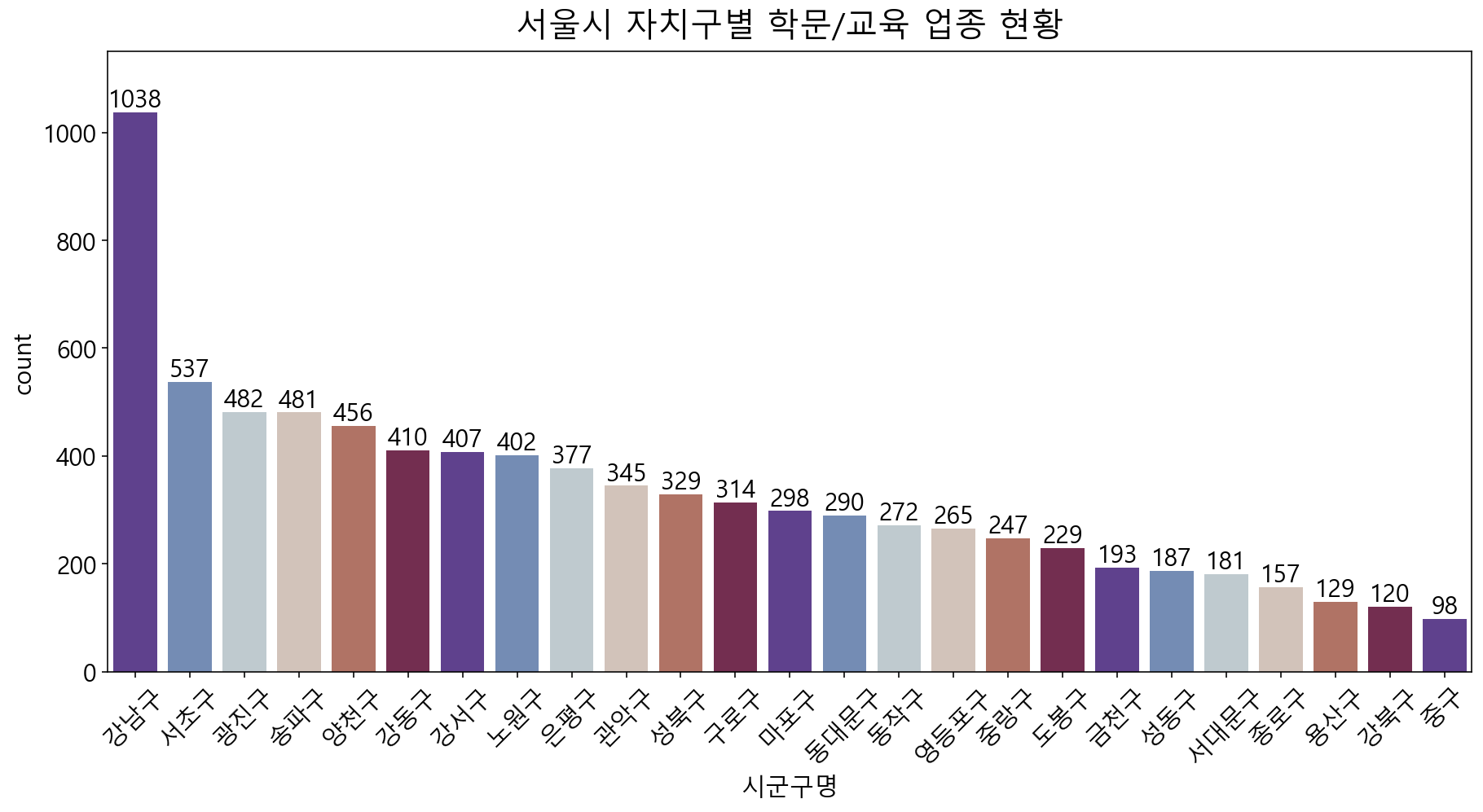
= df_academy['시군구명' ].value_counts()= plt.figure(figsize= (15 , 7 ))= plt.title("서울시 자치구별 학문/교육 업종 현황" , fontsize= 20 , pad= 10 )= sns.countplot(data= df_academy, x= "시군구명" , palette= sns.color_palette("twilight_shifted" ), order= sr_order.index)for i, b in enumerate (bars.patches):= plt.text(b.get_x()+ b.get_width()* (1 / 2 ),b.get_height()+ 10 , \ round (b.get_height()),ha= 'center' ,fontsize= 15 , color= 'black' )= plt.ylim(0 , 1150 )= plt.xticks(rotation= 45 )
학문/교육 업종은 강남구가 가장 많은 비율을 차지하고 있습니다. 그 다음으로는 서초구, 광진구, 송파구 등 비등비등한 개수로 점차 줄어듭니다.
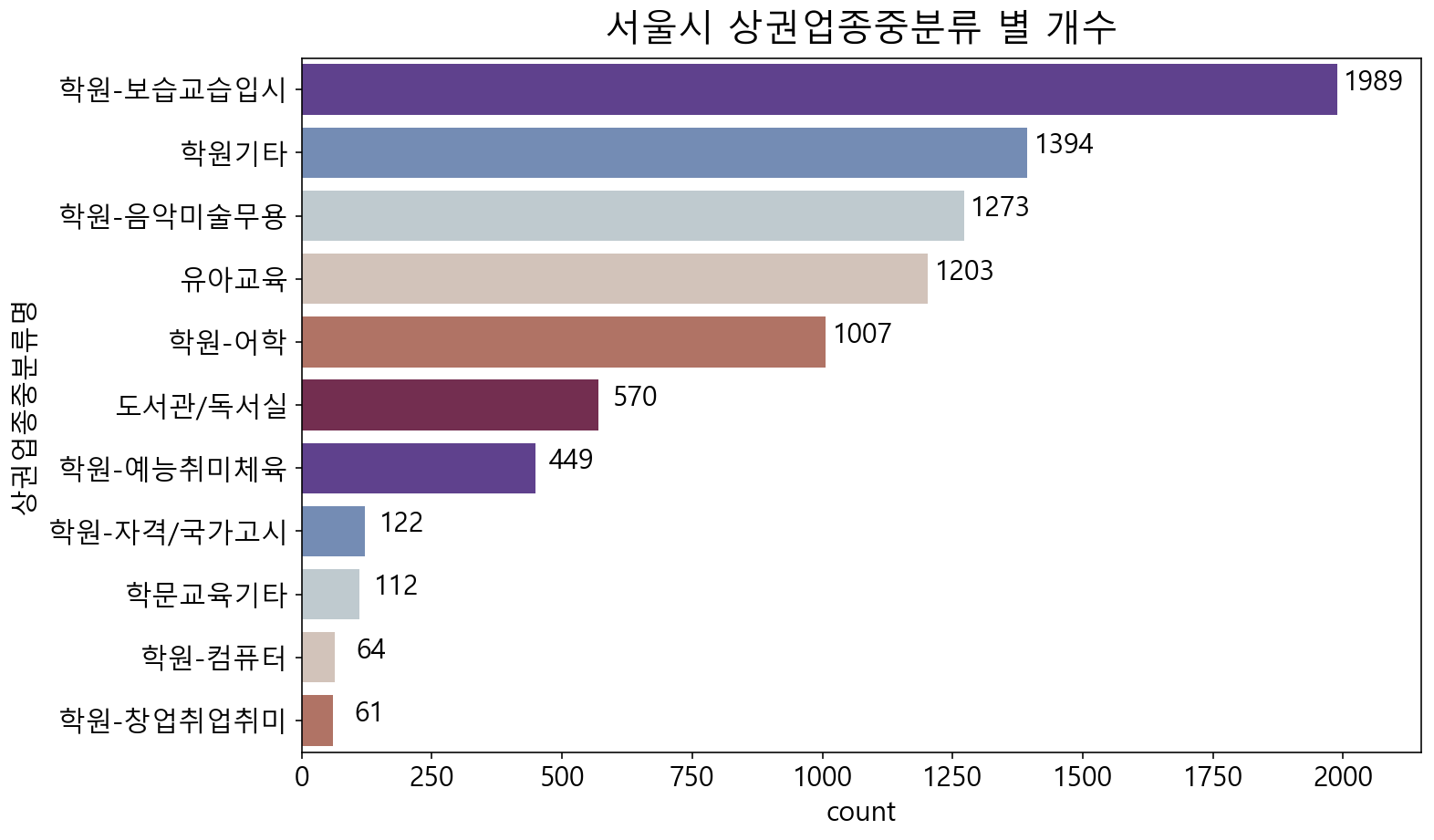
= df_academy['상권업종중분류명' ].value_counts()= plt.figure(figsize= (11 , 7 ))= plt.title("서울시 상권업종중분류 별 개수" , fontsize= 20 , pad= 10 )= sns.countplot(data= df_academy, y= "상권업종중분류명" , palette= sns.color_palette("twilight_shifted" ), order= sr_order.index)for i, b in enumerate (bars.patches):= plt.text(b.get_width()+ 70 ,b.get_y()+ b.get_height()* (1 / 2 ), \ round (b.get_width()),ha= 'center' ,fontsize= 15 , color= 'black' )= plt.xlim(0 , 2150 )
중분류 업종으로 나눠봤을 때는, 보습교습입시가 가장 많은 것으로 나타났습니다.
상권업종 소분류명 top 30개 개수 확인하기
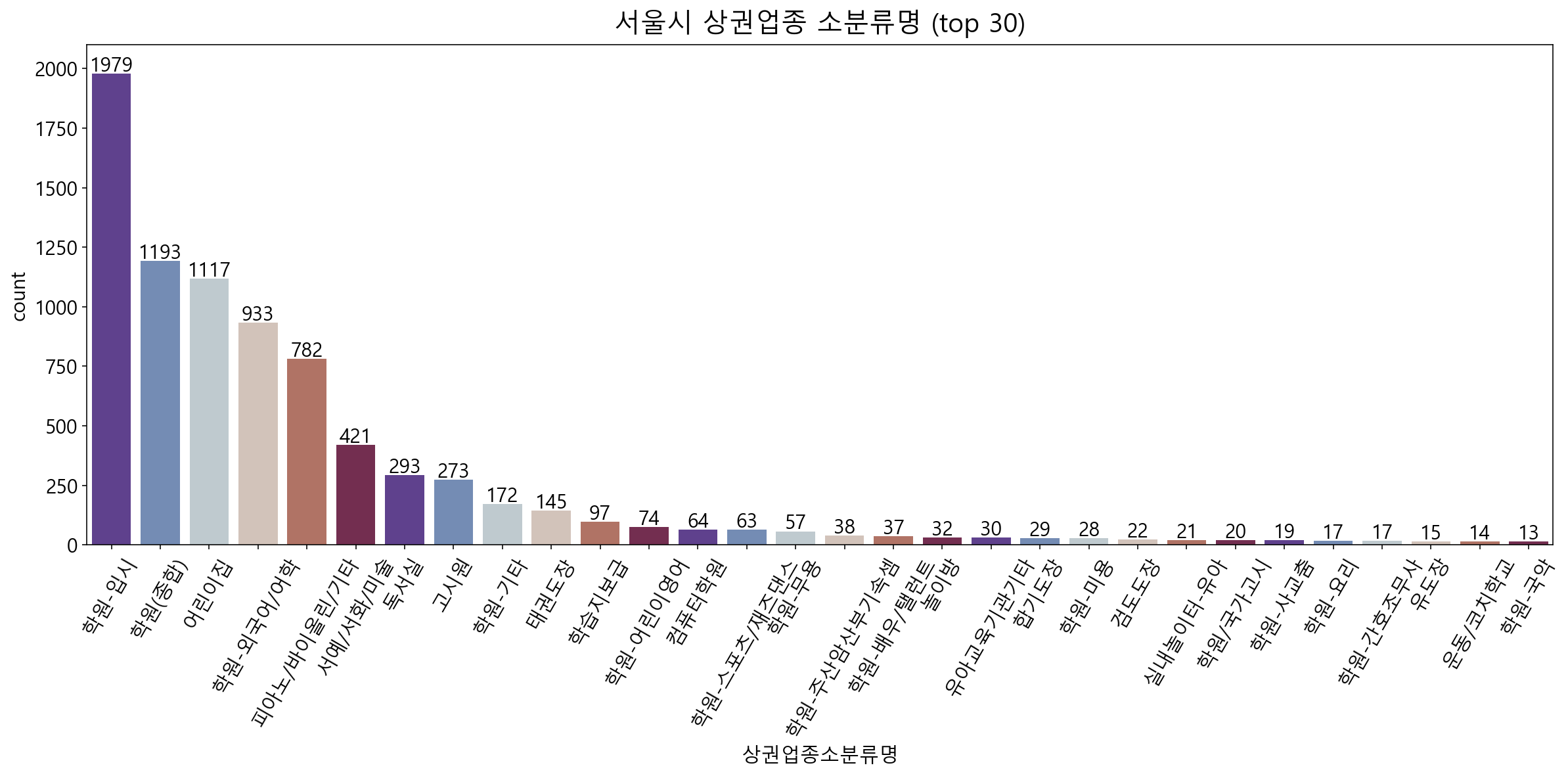
= df_academy['상권업종소분류명' ].value_counts().head(30 )= plt.figure(figsize= (20 , 7 ))= plt.title("서울시 상권업종 소분류명 (top 30)" , fontsize= 20 , pad= 10 )= sns.countplot(data= df_academy, x= "상권업종소분류명" , palette= sns.color_palette("twilight_shifted" ), order= sr_order.index)for i, b in enumerate (bars.patches):= plt.text(b.get_x()+ b.get_width()* (1 / 2 ),b.get_height()+ 10 , \ round (b.get_height()),ha= 'center' ,fontsize= 15 , color= 'black' )= plt.ylim(0 , 2100 )= plt.xticks(rotation= 60 )
소분류명별 시각화를 진행해보니, 학원의 입시와 종합이 가장 많았으며, 어린이집도 높은 비율을 차지하고있습니다.
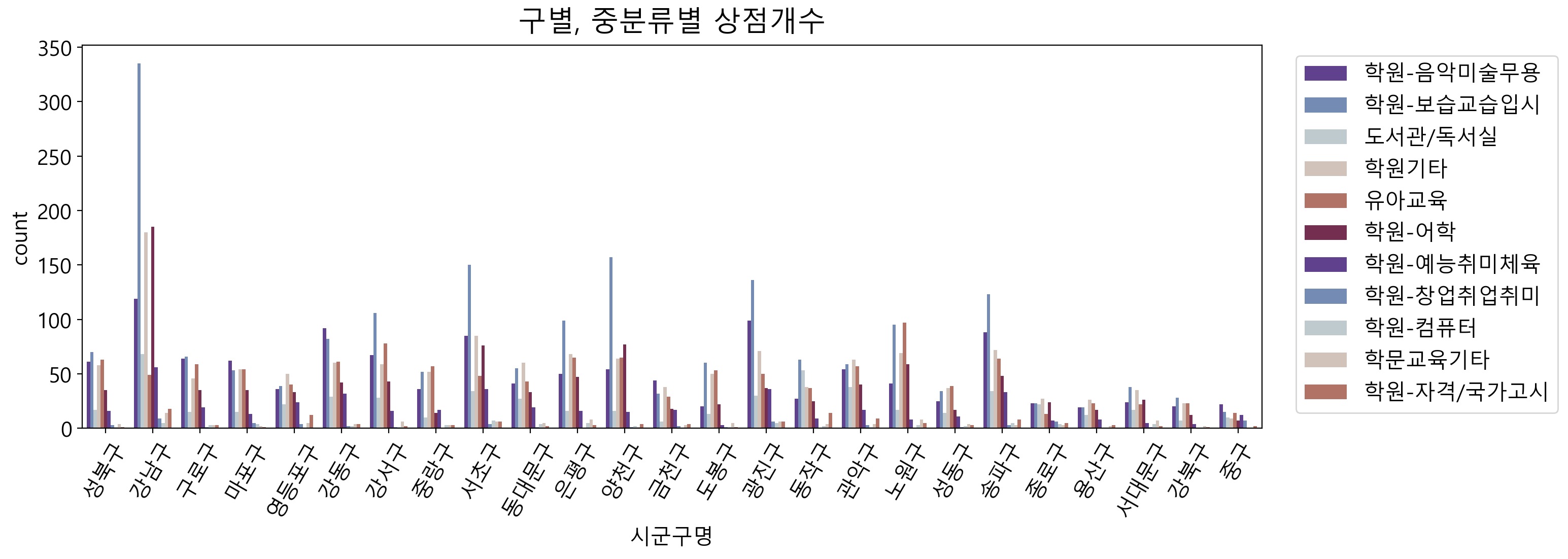
= plt.figure(figsize= (15 ,5 ),dpi= 100 )= plt.title("구별, 중분류별 상점개수" , fontsize= 20 , pad= 10 )= sns.countplot(data= df_academy, x= '시군구명' ,hue= '상권업종중분류명' , palette= sns.color_palette("twilight_shifted" ))= plt.xticks(rotation= 60 )= plt.legend(bbox_to_anchor= (1.02 , 1 ), loc= 2 )
서울시의 자치구 별로 중분류별 상점개수 시각화를 해보았습니다. 특히 강남구에 학원-보습교습입시가 뚜렷하게 높이 솟아있는 것을 볼 수 있습니다. 또, 대체적으로 학원-보습교습입시의 상점 개수가 가장 많은 것으로 보입니다.
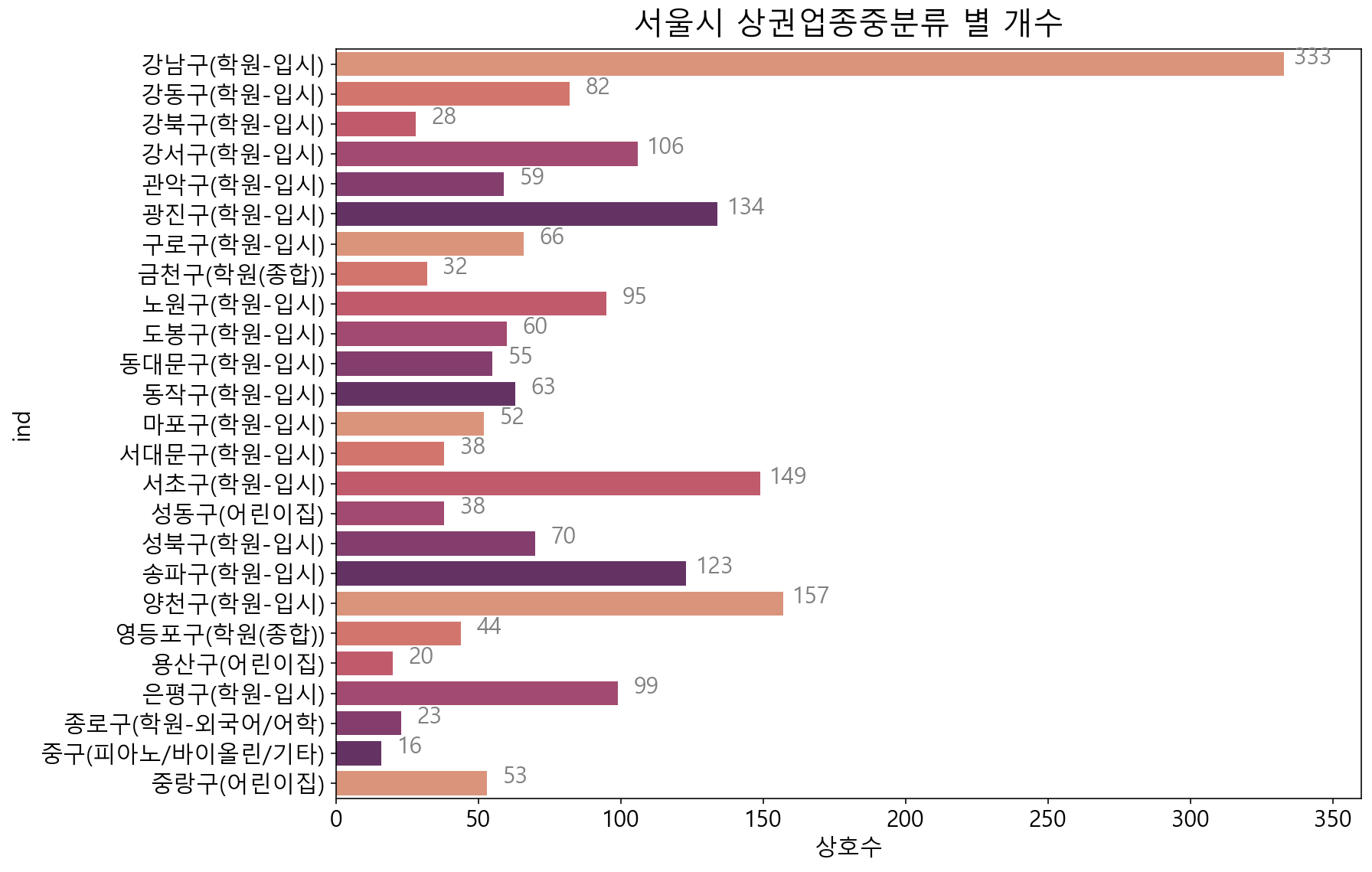
자치구별 가장 많은 소분류명 상점과 그 개수 시각화
# 자치구별 상권업종 소분류명의 개수 = df_academy.groupby(['시군구명' ,'상권업종소분류명' ])['상호명' ].count()= academy_count_s.reset_index()= df2.rename(columns= {'상호명' :'상호수' })= df2.groupby(['시군구명' ])['상호수' ].idxmax()= df2.loc[max_num_index]'ind' ]= df3['시군구명' ]+ '(' + df5['상권업종소분류명' ] + ')' = df3.set_index('ind' )= df3.drop(columns= ['시군구명' ,'상권업종소분류명' ])
시군구명
상권업종소분류명
상호수
ind
46
강남구
학원-입시
333
강남구(학원-입시)
81
강동구
학원-입시
82
강동구(학원-입시)
99
강북구
학원-입시
28
강북구(학원-입시)
126
강서구
학원-입시
106
강서구(학원-입시)
149
관악구
학원-입시
59
관악구(학원-입시)
상호수
ind
강남구(학원-입시)
333
강동구(학원-입시)
82
강북구(학원-입시)
28
강서구(학원-입시)
106
관악구(학원-입시)
59
= plt.figure(figsize= (12 , 9 ))= plt.title("서울시 상권업종중분류 별 개수" , fontsize= 20 , pad= 10 )= sns.barplot(data= df3.reset_index(), = "상호수" ,= 'ind' ,= sns.color_palette("flare" ))for i, b in enumerate (bars.patches):= plt.text(b.get_width()+ 10 ,b.get_y()+ b.get_height()* (1 / 2 ), \ round (b.get_width()),ha= 'center' ,fontsize= 15 , color= 'gray' )= plt.xlim(0 , 360 )
대체적으로 학원-입시 소분류가 가장 많습니다. 다른 학원 (종합, 외국어/어학)도 있고, 어린이집이 가장 많은 자치구도 존재합니다.
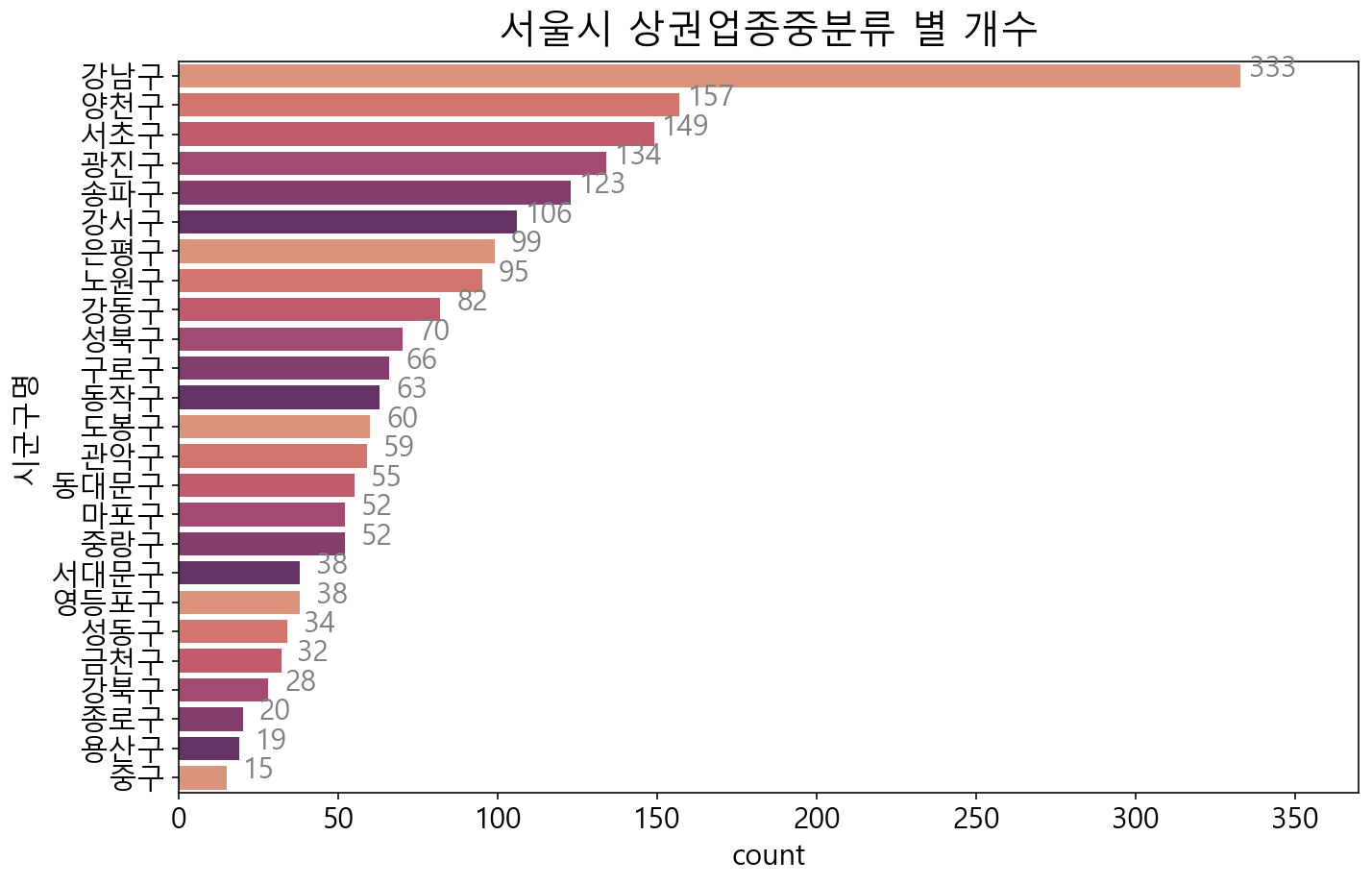
4.2.2 학원-입시가 가장 많은 지역은?
= df_academy.groupby(["상권업종소분류명" , "시군구명" ])["상호명" ].count()= g.loc["학원-입시" ].sort_values(ascending= False )= plt.figure(figsize= (11 , 7 ))= plt.title("서울시 상권업종중분류 별 개수" , fontsize= 20 , pad= 10 )= sns.countplot(data= df_academy[df_academy["상권업종소분류명" ]== "학원-입시" ], = "시군구명" , = sns.color_palette("flare" ), = sr_order.index)for i, b in enumerate (bars.patches):= plt.text(b.get_width()+ 10 ,b.get_y()+ b.get_height()* (1 / 2 ), \ round (b.get_width()),ha= 'center' ,fontsize= 15 , color= 'gray' )= plt.xlim(0 , 370 )
학원-입시 상점 개수를 자치구별로 통계낸 시각화입니다. 강남구가 다른 지역의 2배 이상은 되는 양입니다.
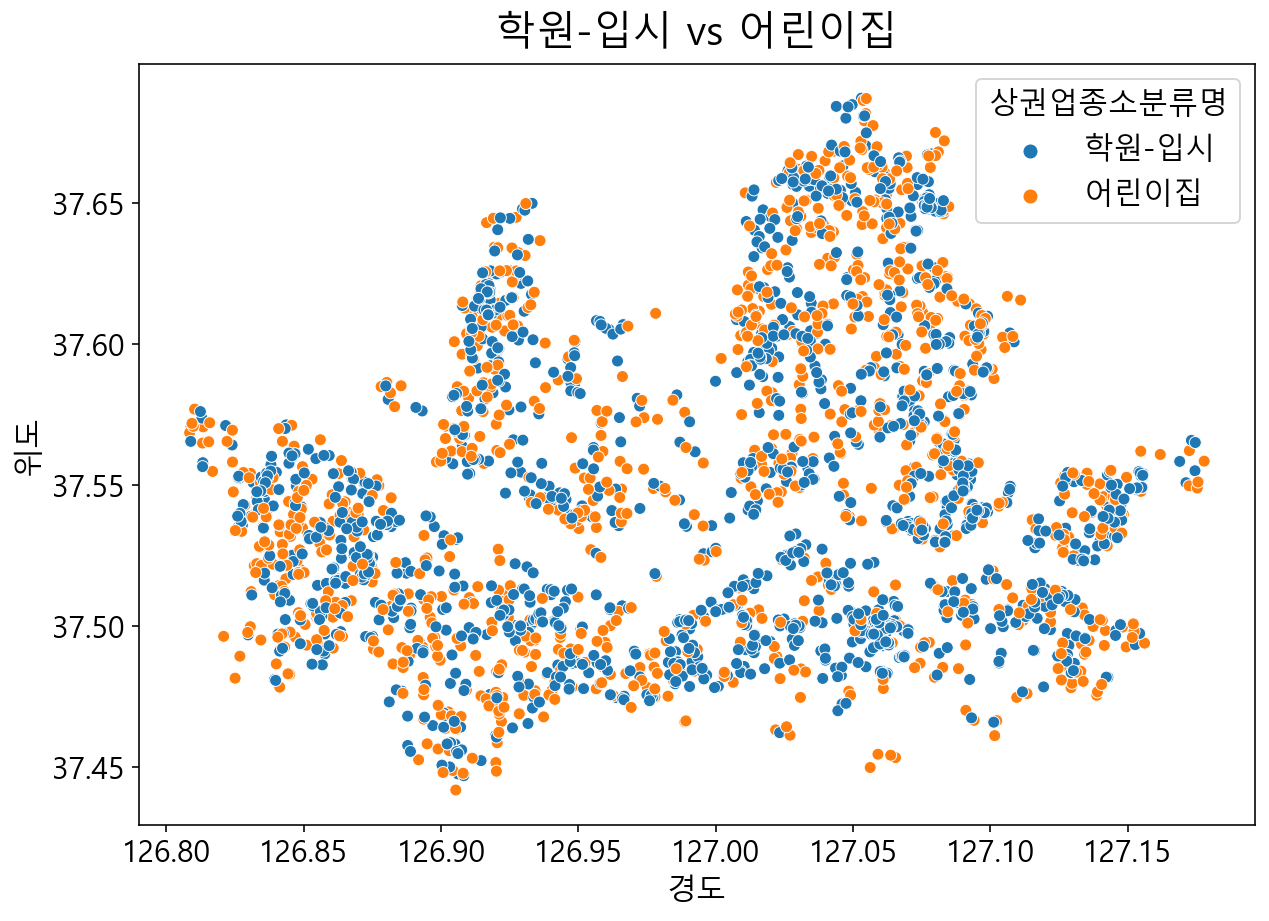
4.2.3 학원-입시 vs 어린이집 비교하기
상권업종 소분류명별 상점 개수에서 1, 3위를 차지했던 학원-입시와 어린이집을 지도에 그려보겠습니다.
# 어린이집과 학원-입시를 비교해 봅니다. = plt.figure(figsize= (10 , 7 ))= plt.title("학원-입시 vs 어린이집" , fontsize= 20 , pad= 10 )= sns.scatterplot(data= df_academy.loc[df_academy["상권업종소분류명" ].isin(["어린이집" , "학원-입시" ])],= "경도" , y= "위도" , hue= "상권업종소분류명" )
먼저, 전체 서울시 지역에 대해서 학원/입시 와 어린이집을 scatter plot으로 그려보았습니다. 산점도에 위도와 경도를 그려봄으로써 대략적인 분포도를 확인할 수 있습니다.
= df.loc[df["시군구명" ].isin(["도봉구" ,"성동구" ]) & (df["상권업종대분류명" ] == "학문/교육" )].copy()= df_academy.loc[df_academy["상권업종소분류명" ].isin(["어린이집" , "학원-입시" ])]= df_m["위도" ].mean()long = df_m["경도" ].mean()= folium.Map(location= [lat, long ], zoom_start= 12 )= df_m.loc[df_m['상권업종소분류명' ]== '학원-입시' ]for i in df_m_ex.index:= df_m.loc[i, "상호명" ] + "(" + df_m.loc[i, "도로명주소" ]+ ")" = df_m.loc[i, "위도" ]long = df_m.loc[i, "경도" ]= folium.Marker([lat, long ], tooltip= t1, radius= 2 , icon= folium.Icon(color= "green" )).add_to(m)= df_m.loc[df_m['상권업종소분류명' ]== '어린이집' ]for i in df_m_ch.index:= df_m.loc[i, "상호명" ] + "(" + df_m.loc[i, "도로명주소" ]+ ")" = df_m.loc[i, "위도" ]long = df_m.loc[i, "경도" ]= folium.Marker([lat, long ], tooltip= t1, radius= 2 , icon= folium.Icon(color= "red" )).add_to(m)
Make this Notebook Trusted to load map: File -> Trust Notebook
folium 라이브러리를 이용하여, 도봉구와 성동구에 대해서만 어린이집과 학원-입시 상점을 시각화 해보았습니다. 초록색이 학원-입시, 빨간색이 어린이집입니다. 두가지 상점의 분포도 파악이나, 실제 위치정보까지 알 수 있는 유용한 라이브러리입니다.
여기까지 공공데이터포털의 소상공인시장진흥공단_상가(상권)정보 데이터를 사용하여 시각화해보았습니다. 시각화 연습용으로 데이터의 개수를 줄여서 진행하였는데, 전체 데이터를 가지고 여러 주제로 분석이 가능해 보입니다. 이 글에서는 교육 업종 현황을 파악해보면서, 어느 지역에 입시 학원이 많은지에 대한 정보를 얻을 수 있었습니다. 또 다른 특정 상권업종분류 업종을 사용하여, 입점분석이나 해당 업종의 현황 파악, 업종이 발달한 지역 등을 분석해 보는 것도 흥미로울 것 같습니다.