이전 글 2.1 주가 데이터셋 보조지표 추가까지 주가 데이터에 보조지표를 추가하여 설명변수를 50개 가량 늘렸다. 그런데 현재 사용하고 있는 통합 종목 주가 데이터는 종목마다 가격이 다르다는 문제점이 존재한다. 이는 성능을 저하시기는 원인이 될 수 있다. 따라서 주가 데이터셋의 전처리 파트에서 스케일링은 매우 중요한 요소라고할 수 있다. min-max scaling을 여러 방법으로 시도하고, 전 날 종가로 나누는 div-close 방법을 사용하여 총 4가지 스케일링 성능을 비교해보도록 하겠다.
목차
스케일러 비교
스케일러 선택
필요 라이브러리 import
import pandas as pdimport numpy as npfrom tqdm import tqdmimport FinanceDataReader as fdrimport pymysqlimport warningswarnings.filterwarnings('ignore')import tafrom ipywidgets import interact, interact_manualimport matplotlib.pyplot as pltimport seaborn as snsimport plotly.graph_objects as goimport plotly.offline as pyo%matplotlib inline%pylab inlinepylab.rcParams['figure.figsize'] = (12,5)# 자주쓰는 함수들은 모듈화 함 import StockFunc as sf
Populating the interactive namespace from numpy and matplotlib
✔️ (1) 스케일러 비교
1) min-max scaler (전체 컬럼 + 전체 데이터)
모든 컬럼을 독립적으로 종목 별 전체데이터에 대해 min-max scaling 한다.
def make_dataset_minmax(trading):from sklearn.preprocessing import MinMaxScaler# 종목코드 불러오기 IF =open('../data/code_list.txt') lst_code = IF.readlines() lst_X = [] lst_Y = [] lst_code_date = [] db_dsml = pymysql.connect( host ='localhost', port =3306, user ='[db username]', passwd ='[db password]', db ='[db name]', charset ='utf8' ) cursor = db_dsml.cursor()for code in tqdm(lst_code): code = code.strip() sql_query =''' SELECT * FROM stock_{0} WHERE Date BETWEEN '2017-01-01' AND '2021-12-31' '''.format(code) stock = pd.read_sql(sql = sql_query, con = db_dsml) stock['trading_value'] = stock['Close'] * stock['Volume'] lst_stock = stock.values.tolist()# 🌟 scaling df_temp = stock.drop(columns=['Date', 'Change', 'Next Change']) scaler = MinMaxScaler() scaled = scaler.fit_transform(df_temp) lst_stock_scaled = scaled.tolist()for idx, row inenumerate(lst_stock): date, trading_value = row[0].date().strftime("%Y-%m-%d"), row[-1]if trading_value >= trading:if (idx <9) or (idx >=len(lst_stock)-1): # 예외 처리 continue# D-9 ~ D0 데이터만 담기 sub_stock = lst_stock_scaled[idx-9:idx+1] # 10일간의 데이터 lst_result = []for row2 in sub_stock: lst_result += row2# D+1 종가 2% 상승 여부 label =int(row[7] >=0.02)# 종속변수, 독립변수, 종목코드, 날짜 리스트에 추가 lst_X.append(lst_result) lst_Y.append(label) lst_code_date.append([code, date])return pd.concat([pd.DataFrame(lst_code_date), pd.DataFrame(lst_X), pd.DataFrame(lst_Y)], axis=1)
[15:05:37] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[16:05:07] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[16:15:14] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[16:26:12] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
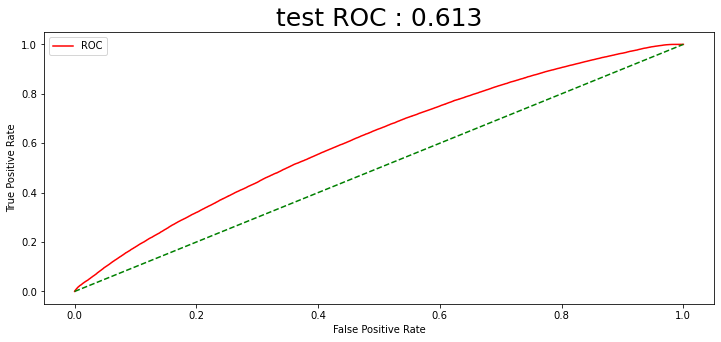
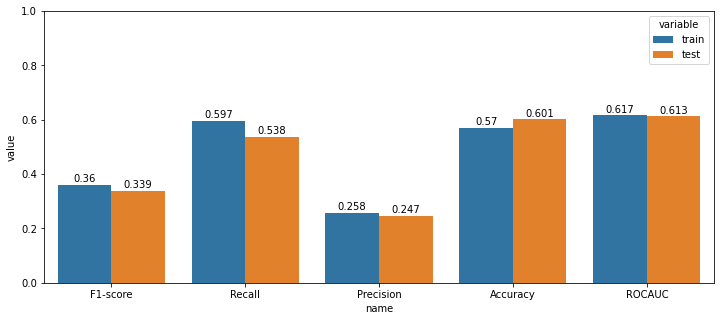
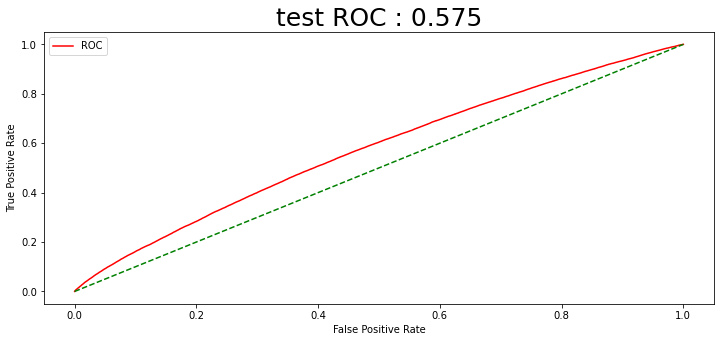
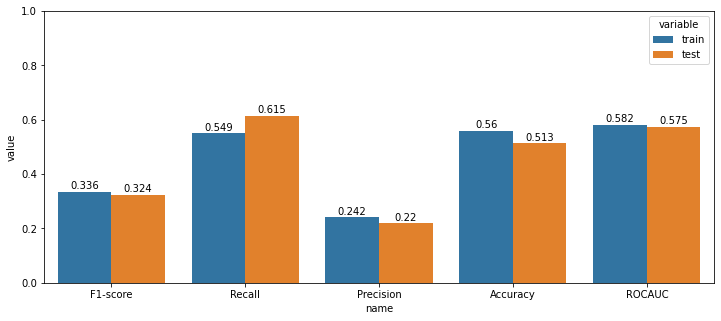
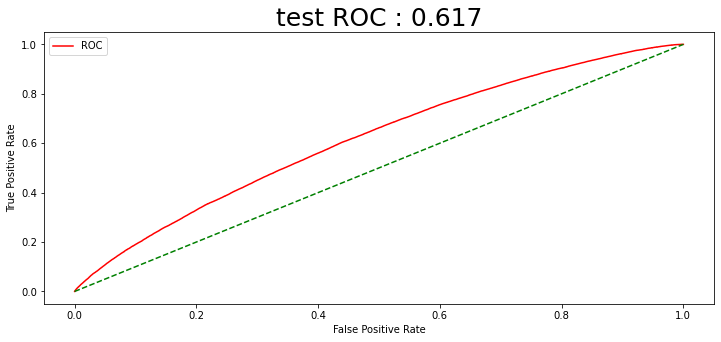
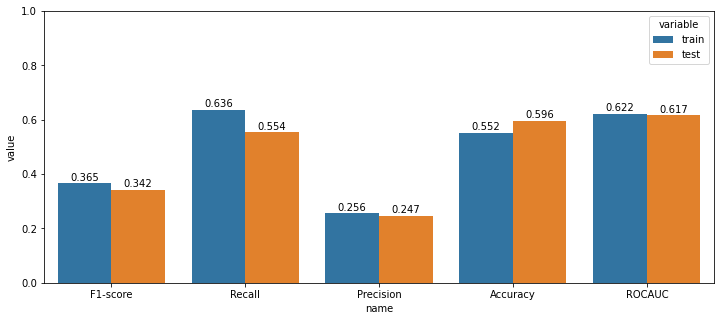
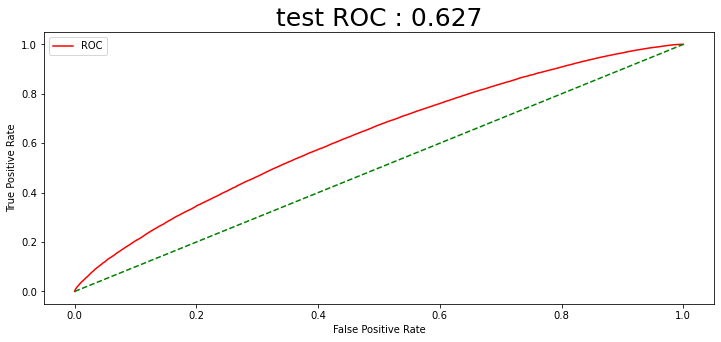
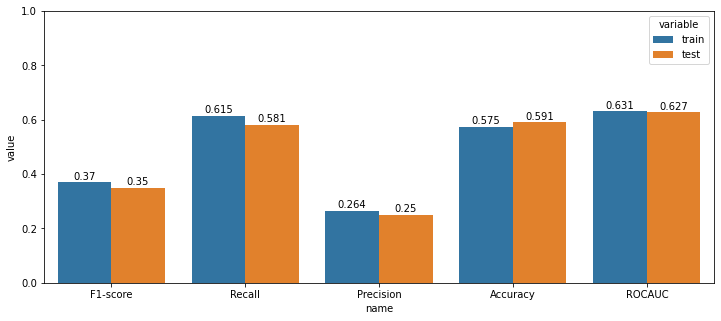
예측확률 임계값을 0.75로 설정하였는데, 4) 전 날 종가로 나누기 방법의 스케일링이 가장 매매 개수가 많았다. 1년 동안 130번의 매수가 일어났음을 알 수 있다. 그와 동시에 수익률 시뮬레이션에서 수익률이 가장 높게 나온 전 날 종가로 나누는 스케일링 방법을 최종적으로 선택한다.