이전 글 ( 3.1. 설명가능 AI (XAI), SHAP value ) 에서는 XAI 기법 중 하나인 SHAP을 사용하여 변수 중요도를 계산하고, summary plot의 결과로 데이터를 필터링하여 특정 집단을 구성해보았다. 이번 글에서는 주가 데이터셋과, SHAP표준화 데이터셋을 2차원 평면에 시각화함으로써 집단 형성이 이루어지는 것을 확인한다.
목차
SHAP 표준화 데이터셋
T-SNE를 사용한 2차원 시각화 비교 (원본 데이터셋 vs SHAP transform 데이터셋)
라이브러리 import
import pandas as pdimport numpy as npfrom tqdm import tqdmimport pymysqlimport warningswarnings.filterwarnings('ignore')from ipywidgets import interact, interact_manualimport matplotlib.pyplot as pltimport seaborn as snsimport plotly.graph_objects as goimport plotly.offline as pyo%matplotlib inline%pylab inlinepylab.rcParams['figure.figsize'] = (12,5)import StockFunc as sf
%pylab is deprecated, use %matplotlib inline and import the required libraries.
Populating the interactive namespace from numpy and matplotlib
(1) SHAP 표준화 데이터셋
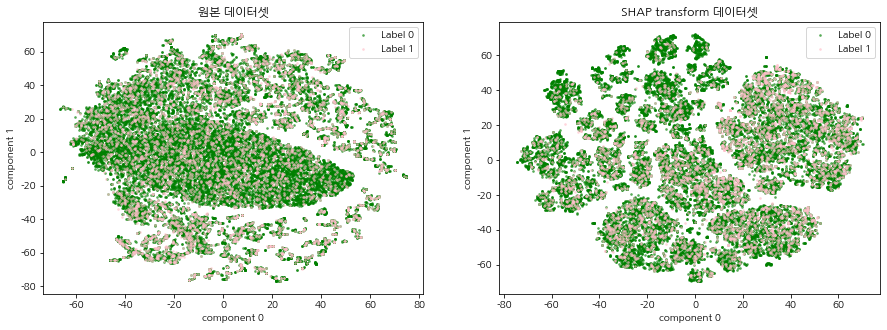
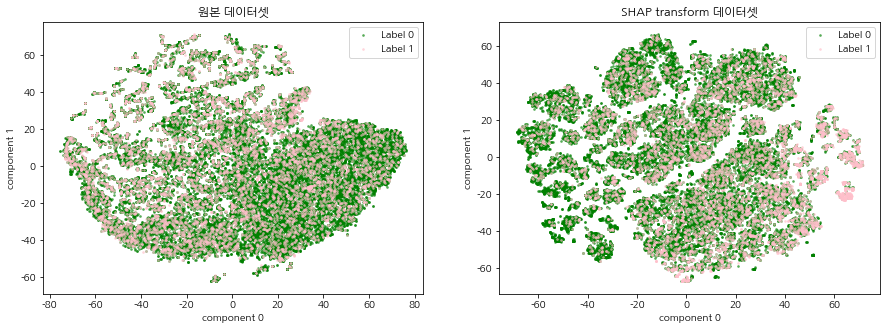
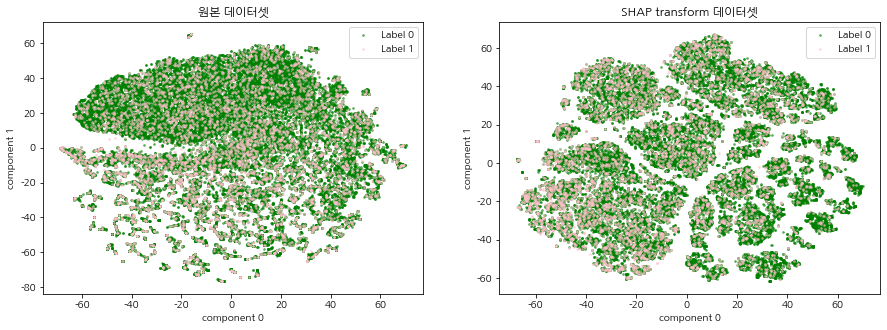
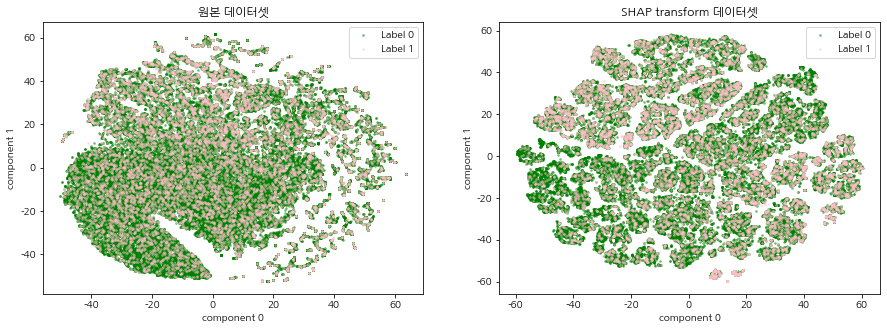
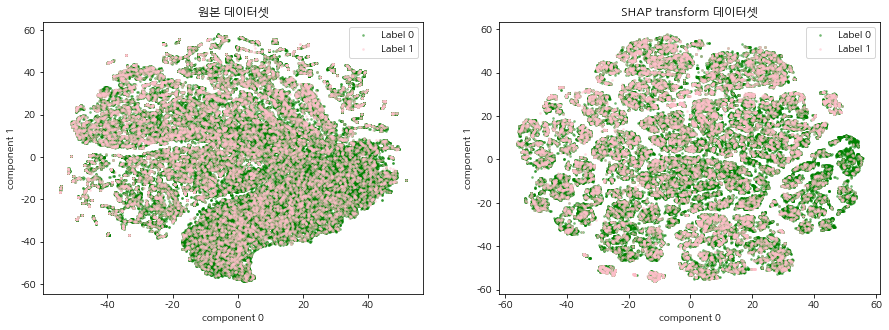
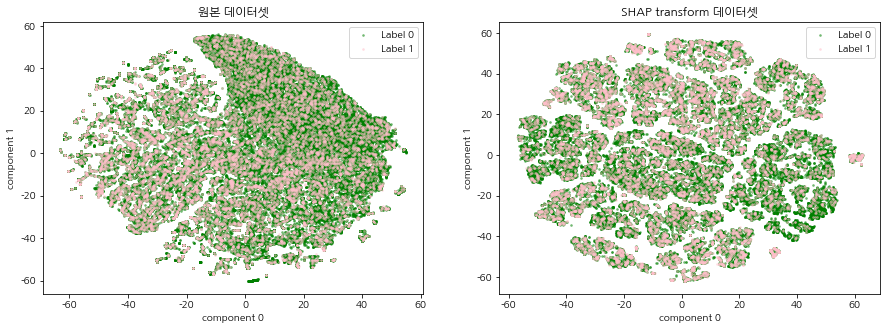
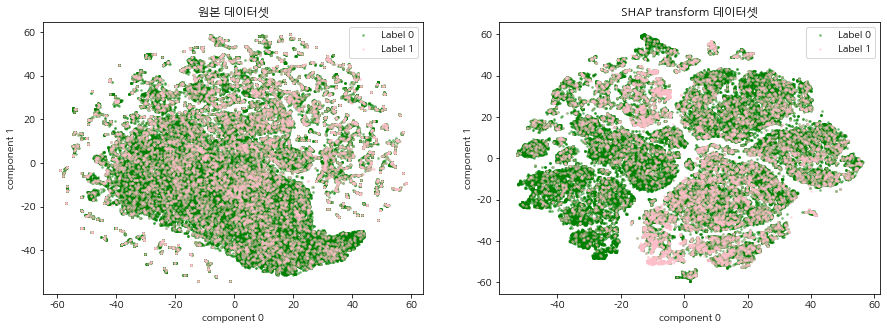
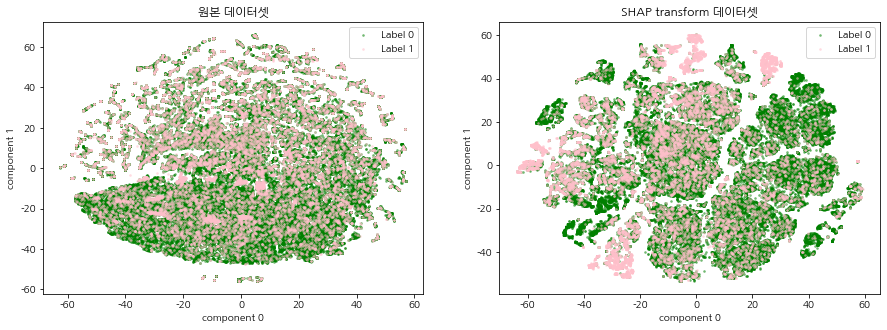
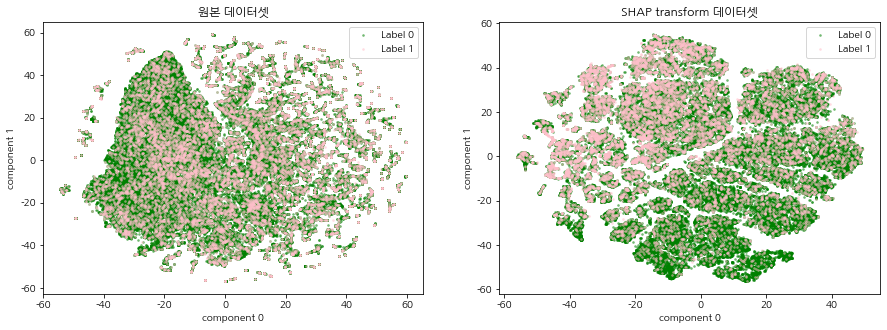
SHAP 표준화 데이터셋이란 주가 예측 머신러닝 모델(XGBoost)로 각 데이터에 대한 Shap value를 계산하여 기존의 주가 데이터셋을 변환한 데이터를 말한다. 기존 주가 데이터가 SHAP 표준화 데이터로 변환되었을 때, 이진분류 주가 예측 모델의 중요 변수를 상대적으로 가중하게됨으로써 데이터에서의 내재되어있는 패턴이 강조되는 효과가 있다. 따라서 기존의 주가 데이터셋과 SHAP 표준화 데이터셋을 2차원 평면에 함께 시각화 하여 SHAP 표준화 데이터셋의 군집의 경계가 더 명확하게 드러나는 것을 확인한다.
CCI 구간 별 주가 데이터셋 불러오기
import picklewithopen('dataset_cci_filtering.pickle', 'rb') as handle: dic_dataset_model = pickle.load(handle)
(2) T-SNE를 사용한 2차원 시각화 비교 (원본 데이터셋 vs SHAP 표준화 데이터셋)
2차원 시각화는 CCI 구간별, 연도별로 데이터를 분할하여 진행한다. 이 때 원본 주가 데이터셋과 SHAP 표준화 데이터셋을 같이 시각화하여 군집이 형성되는 형태를 비교한다.
데이터 분할에 사용되는 CCI 구간, 연도는 다음과 같다.
*CCI 구간 1) 중립구간 - CCI : (-20, 20) 2) 과열구간 - CCI : (100, \(\infty\)) 3) 침체 구간 - CCI : (-\(\infty\),-100)
*연도 1) 2019년 2) 2020년 3) 2021년
t-SNE 2차원 시각화 함수 생성
원본 주가 데이터셋과 SHAP 표준화 데이터셋, 연도, cci 구간 정보를 넣어주면, 두 데이터셋에 대한 2차원 시각화 결과를 반환하는 함수를 생성한다. 시간 단축을 위해 최초 실행할 때 tsne_load=False로 설정하여 tsne 데이터를 저장하고, tsne_loae=True로 바꾸어 바로 시각화 할 수 있도록 한다. 2차원 시각화 할 때는 label별로 색깔을 다르게 지정하여 특정 label의 분포가 집중되어 있는 군집이 존재하는지 확인한다.
def tsne_visualization(dataset, shap_dataset, year, cci_type, tsne_load=False, alpha=0.4, size=3):""" dataset: pd.DataFrame() / 원본 주가 데이터셋 shap_dataset: pd.DataFrame() / SHAP 표준화 데이터셋 year: Int / 시각화 할 연도 cci_type: Int / 1(중립구간), 2(과열구간), 3(침체구간) - 파일 저장 및 로드를 위함 tsne_load(default:True): Boolean / False: 최초 실행 시 tsne data 생성 후 저장, True: 저장된 tsne data를 불러와서 시각화 - 시간 절약을 위함 alpha(default:0.4): Float / 투명도 size=3(default:3): Int / 점 크기 """from sklearn.manifold import TSNEimport pickle plt.rcParams['axes.unicode_minus'] =False plt.rc('font', family='NanumGothic')# plt.style.use('default') fig = plt.figure(figsize=(15, 5)) ax1, ax2 = fig.subplots(1, 2)##### 원본 데이터 ##### dataset_year = dataset[(dataset['Date'] >=f'{year}-01-01') & (dataset['Date'] <=f'{year}-12-31')].reset_index(drop=True)ifnot tsne_load: np_tsne = TSNE(n_components=2, random_state=42).fit_transform(dataset_year.drop(columns=['Code', 'Date', 'Label'])) # 2차원 t-sne 임베딩 # save np_tsnewithopen(f'np_tsne_{year}_{cci_type}', 'wb') as handle: pickle.dump(np_tsne, handle, protocol=pickle.HIGHEST_PROTOCOL)else: # load np_tsnewithopen(f'np_tsne_{year}_{cci_type}', 'rb') as handle: np_tsne = pickle.load(handle) df_tsne = pd.DataFrame(np_tsne, columns=['component0', 'component1']) # numpy array -> Dataframe df_tsne['Label'] = dataset_year['Label'] # Label 정보 불러오기# Label 별 분리 df_tsne_0 = df_tsne[df_tsne['Label']==0] df_tsne_1 = df_tsne[df_tsne['Label']==1]# Label 별 시각화 ax1.scatter(df_tsne_0['component0'], df_tsne_0['component1'], color ='green', label ='Label 0', alpha=alpha, s=size) ax1.scatter(df_tsne_1['component0'], df_tsne_1['component1'], color ='pink', label ='Label 1', alpha=alpha, s=size) ax1.set_title('원본 데이터셋') ax1.set_xlabel('component 0') ax1.set_ylabel('component 1') ax1.legend()##### SHAP transform data ##### shap_dataset_year = shap_dataset[(shap_dataset['Date'] >=f'{year}-01-01') & (shap_dataset['Date'] <=f'{year}-12-31')].reset_index(drop=True)ifnot tsne_load: np_tsne_shap = TSNE(n_components=2, random_state=42).fit_transform(shap_dataset_year.drop(columns=['Code', 'Date', 'Label'])) # 2차원 t-sne 임베딩 # save np_tsnewithopen(f'np_tsne_shap_{year}_{cci_type}', 'wb') as handle: pickle.dump(np_tsne_shap, handle, protocol=pickle.HIGHEST_PROTOCOL)else: # load np_tsnewithopen(f'np_tsne_shap_{year}_{cci_type}', 'rb') as handle: np_tsne_shap = pickle.load(handle) df_tsne_shap = pd.DataFrame(np_tsne_shap, columns=['component0', 'component1']) # numpy array -> Dataframe df_tsne_shap['Label'] = shap_dataset_year['Label'] # Label 정보 불러오기# Label 별 분리 df_tsne_shap_0 = df_tsne_shap[df_tsne_shap['Label']==0] df_tsne_shap_1 = df_tsne_shap[df_tsne_shap['Label']==1]# Label 별 시각화 ax2.scatter(df_tsne_shap_0['component0'], df_tsne_shap_0['component1'], color ='green', label ='Label 0', alpha=alpha, s=size) ax2.scatter(df_tsne_shap_1['component0'], df_tsne_shap_1['component1'], color ='pink', label ='Label 1', alpha=alpha, s=size) ax2.set_title('SHAP transform 데이터셋') ax2.set_xlabel('component 0') ax2.set_ylabel('component 1') ax2.legend() plt.show()
CCI 구간 별, 연도 별 t-SNE 시각화를 진행한다. 원본 데이터셋과 SHAP transform 데이터셋의 그림을 비교하여 집단 형성이 이루어지는지 확인한다.
모든 CCI 구간, 연도에서 원본 주가 데이터셋 보다 SHAP 표준화 데이터셋의 군집의 경계가 더 명확하게 드러났으며, 특정 label의 분포 또한 집중되어있는 군집이 존재함을 확인할 수 있다. 이는 SHAP 표준화 데이터셋을 사용함으로써, 예측 모델의 중요 변수를 상대적으로 가중하게되어 데이터에서의 내재되어있는 패턴이 강조되는 효과가 나타난 것으로 해석된다. 본 글에서 군집이 나누어지는 것을 확인하였다면, 다음 글에서는 SHAP 표준화 데이터셋에 대하여 실제로 클러스터링 알고리즘을 적용하여 군집을 명시적으로 분류하는 시간을 가진다.